(Heads up — this article was published in October 2020. Much of the general discussion is still relevant, but many of these SoCs are getting quite long in the tooth, and some of the software issues mentioned here have been addressed)
After I published my $1 MCU write-up, several readers suggested I look at application processors — the MMU-endowed chips necessary to run real operating systems like Linux. Massive shifts over the last few years have seen internet-connected devices become more featureful (and hopefully, more secure), and I’m finding myself putting Linux into more and more places.
Among beginner engineers, application processors supplicate reverence: one minor PCB bug and your $10,000 prototype becomes a paperweight. There’s an occult consortium of engineering pros who drop these chips into designs with utter confidence, while the uninitiated cower for their Raspberry Pis and overpriced industrial SOMs.
This article is targeted at embedded engineers who are familiar with microcontrollers but not with microprocessors or Linux, so I wanted to put together something with a quick primer on why you’d want to run embedded Linux, a broad overview of what’s involved in designing around application processors, and then a dive into some specific parts you should check out — and others you should avoid — for entry-level embedded Linux systems.
Just like my microcontroller article, the parts I picked range from the well-worn horses that have pulled along products for the better part of this decade, to fresh-faced ICs with intriguing capabilities that you can keep up your sleeve.
If my mantra for the microcontroller article was that you should pick the right part for the job and not be afraid to learn new software ecosystems, my argument for this post is even simpler: once you’re booted into Linux on basically any of these parts, they become identical development environments.
That makes chips running embedded Linux almost a commodity product: as long as your processor checks off the right boxes, your application code won’t know if it’s running on an ST or a Microchip part — even if one of those is a brand-new dual-core Cortex-A7 and the other is an old ARM9. Your I2C drivers, your GPIO calls — even your V4L-based image processing code — will all work seamlessly.
At least, that’s the sales pitch. Getting a part booted is an entirely different ordeal altogether — that’s what we’ll be focused on. Except for some minor benchmarking at the end, once we get to a shell prompt, we’ll consider the job completed.
As a departure from my microcontroller review, this time I’m focusing heavily on hardware design: unlike the microcontrollers I reviewed, these chips vary considerably in PCB design difficulty — a discussion I would be in error to omit. To this end, I designed a dev board from scratch for each application processor reviewed. Well, actually, many dev boards for each processor: roughly 25 different designs in total. This allowed me to try out different DDR layout and power management strategies — as well as fix some bugs along the way.
I intentionally designed these boards from scratch rather than starting with someone else’s CAD files. This helped me discover little “gotchas” that each CPU has, as well as optimize the design for cost and hand-assembly. Each of these boards was designed across one or two days’ worth of time and used JLC’s low-cost 4-layer PCB manufacturing service.
These boards won’t win any awards for power consumption or EMC: to keep things easy, I often cheated by combining power rails together that would typically be powered (and sequenced!) separately. Also, I limited the on-board peripherals to the bare minimum required to boot, so there are no audio CODECs, little I2C sensors, or Ethernet PHYs on these boards.
As a result, the boards I built for this review are akin to the notes from your high school history class or a recording you made of yourself practicing a piece of music to study later. So while I’ll post pictures of the boards and screenshots of layouts to illustrate specific points, these aren’t intended to serve as reference designs or anything; the whole point of the review is to get you to a spot where you’ll want to go off and design your own little Linux boards. Teach a person to fish, you know?
Microcontroller vs Microprocessor: Differences
Coming from microcontrollers, the first thing you’ll notice is that Linux doesn’t usually run on Cortex-M, 8051, AVR, or other popular microcontroller architectures. Instead, we use application processors — popular ones are the Arm Cortex-A, ARM926EJ-S, and several MIPS iterations.
The biggest difference between these application processors and a microcontroller is quite simple: microprocessors have a memory management unit (MMU), and microcontrollers don’t. Yes, you can run Linux without an MMU, but you usually shouldn’t: Cortex-M7 parts that can barely hit 500 MHz routinely go for double or quadruple the price of faster Cortex-A7s. They’re power-hungry: microcontrollers are built on larger processes than application processors to reduce their leakage current. And without an MMU and generally-low clock speeds, they’re downright slow.
Other than the MMU, the lines between MCUs and MPUs are getting blurred. Modern application processors often feature a similar peripheral complement as microcontrollers, and high-end Cortex-M7 microcontrollers often have similar clock speeds as entry-level application processors.
Why would you want to Linux?
When your microcontroller project outgrows its super loop and the random ISRs you’ve sprinkled throughout your code with care, there are many bare-metal tasking kernels to turn to — FreeRTOS, ThreadX (now Azure RTOS), RT-Thread, μC/OS, etc. By an academic definition, these are operating systems. However, compared to Linux, it’s more useful to think of these as a framework you use to write your bare-metal application inside. They provide the core components of an operating system: threads (and obviously a scheduler), semaphores, message-passing, and events. Some of these also have networking, filesystems, and other libraries.
Comparing bare-metal RTOSs to Linux simply comes down to the fundamental difference between these and Linux: memory management and protection. This one technical difference makes Linux running on an application processor behave quite differently from your microcontroller running an RTOS.((Before the RTOS snobs attack with pitchforks, yes, there are large-scale, well-tested RTOSes that are usually run on application processors with memory management units. Look at RTEMS as an example. They don’t have some of the limitations discussed below, and have many advantages over Linux for safety-critical real-time applications.))
Dynamic memory allocation
Small microcontroller applications can usually get by with static allocations for everything, but as your application grows, you’ll find yourself calling malloc() more and more, and that’s when weird bugs will start creeping up in your application. With complex, long-running systems, you’ll notice things working 95% of the time — only to crash at random (and usually inopportune) times. These bugs evade the most javertian developers, and in my experience, they almost always stem from memory allocation issues: usually either memory leaks (that can be fixed with appropriate free() calls), or more serious problems like memory fragmentation (when the allocator runs out of appropriately-sized free blocks).
Because Linux-capable application processors have a memory management unit, *alloc() calls execute swiftly and reliably. Physical memory is only reserved (faulted in) when you actually access a memory location. Memory fragmentation is much less an issue since Linux frees and reorganizes pages behind the scenes. Plus, switching to Linux provides easier-to-use diagnostic tools (like valgrind) to catch bugs in your application code in the first place. And finally, because applications run in virtual memory, if your app does have memory bugs in it, Linux will kill it — leaving the rest of your system running. ((As a last-ditch kludge, it’s not uncommon to call your app in a superloop shell script to automatically restart it if it crashes without having to restart the entire system.))
Networking & Interoperability
Running something like lwIP under FreeRTOS on a bare-metal microcontroller is acceptable for a lot of simple applications, but application-level network services like HTTP can burden you to implement in a reliable fashion. Stuff that seems simple to a desktop programmer — like a WebSockets server that can accept multiple simultaneous connections — can be tricky to implement in bare-metal network stacks. Because C doesn’t have good programming constructs for asynchronous calls or exceptions, code tends to contain either a lot of weird state machines or tons of nested branches. It’s horrible to debug problems that occur. In Linux, you get a first-class network stack, plus tons of rock-solid userspace libraries that sit on top of that stack and provide application-level network connectivity. Plus, you can use a variety of high-level programming languages that are easier to handle the asynchronous nature of networking.
Somewhat related is the rest of the standards-based communication / interface frameworks built into the kernel. I2S, parallel camera interfaces, RGB LCDs, SDIO, and basically all those other scary high-bandwidth interfaces seem to come together much faster when you’re in Linux. But the big one is USB host capabilities. On Linux, USB devices just work. If your touchscreen drivers are glitching out and you have a client demo to show off in a half-hour, just plug in a USB mouse until you can fix it (I’ve been there before). Product requirements change and now you need audio? Grab a $20 USB dongle until you can respin the board with a proper audio codec. On many boards without Ethernet, I just use a USB-to-Ethernet adapter to allow remote file transfer and GDB debugging. Don’t forget that, at the end of the day, an embedded Linux system is shockingly similar to your computer.
Security
When thinking about embedded device security, there are usually two things we’re talking about: device security (making sure the device can only boot from verified firmware), and network security (authentication, intrusion prevention, data integrity checks, etc).
Device security is all about chain of trust: we need a bootloader to read in an encrypted image, decrypt and verify it, before finally executing it. The bootloader and keys need to be in ROM so that they cannot be modified. Because the image is encrypted, nefarious third-parties won’t be able to install the firmware on cloned hardware. And since the ROM authenticates the image before executing, people won’t be able to run custom firmware on the hardware.
Network security is about limiting software vulnerabilities and creating a trusted execution environment (TEE) where cryptographic operations can safely take place. The classic example is using client certificates to authenticate our client device to a server. If we perform the cryptographic hashing operation in a secure environment, even an attacker who has gained total control over our normal execution environment would be unable to read our private key.
In the world of microcontrollers, unless you’re using one of the newer Cortex-M23/M33 cores, your chip probably has a mishmash of security features that include hardware cryptographic support, (notoriously insecure) flash read-out protection, execute-only memory, write protection, TRNG, and maybe a memory protection unit. While vendors might have an app note or simple example, it’s usually up to you to get all of these features enabled and working properly, and it’s challenging to establish a good chain of trust, and nearly impossible to perform cryptographic operations in a context that’s not accessible by the rest of the system.
Secure boot isn’t available on every application processor reviewed here, it’s much more common. While there are still vulnerabilities that get disclosed from time to time, my non-expert opinion is that the implementations seem much more robust than on Cortex-M parts: boot configuration data and keys are stored in one-time-programmable memory that is not accessible from non-privileged code. Network security is also more mature and easier to implement using Linux network stack and cryptography support, and OP-TEE provides a ready-to-roll secure environment for many parts reviewed here.
Filesystems & Databases
Imagine that you needed to persist some configuration data across reboot cycles. Sure, you can use structs and low-level flash programming code, but if this data needs to be appended to or changed in an arbitrary fashion, your code would start to get ridiculous. That’s why filesystems (and databases) exist. Yes, there are embedded libraries for filesystems, but these are way clunkier and more fragile than the capabilities you can get in Linux with nothing other than ticking a box in menuconfig. And databases? I’m not sure I’ve ever seen an honest attempt to run one on a microcontroller, while there’s a limitless number available on Linux.
Multiple Processes
In a bare-metal environment, you are limited to a single application image. As you build out the application, you’ll notice things get kind of clunky if your system has to do a few totally different things simultaneously. If you’re developing for Linux, you can break this functionality into separate processes, where you can develop, debug, and deploy separately as separate binary images.
The classic example is the separation between the main app and the updater. Here, the main app runs your device’s primary functionality, while a separate background service can run every day to phone home and grab the latest version of the main application binary. These apps do not have to interact at all, and they perform completely different tasks, so it makes sense to split them up into separate processes.
Language and Library Support
Bare-metal MCU development is primarily done in C and C++. Yes, there are interesting projects to run Python, Javascript, C#/.NET, and other languages on bare metal, but they’re usually focused on implementing the core language only; they don’t provide a runtime that is the same as a PC. And even their language implementation is often incompatible. That means your code (and the libraries you use) have to be written specifically for these micro-implementations. As a result, just because you can run MicroPython on an ESP32 doesn’t mean you can drop Flask on it and build up a web application server. By switching to embedded Linux, you can use the same programming languages and software libraries you’d use on your PC.
Brick-wall isolation from the hardware
Classic bare-metal systems don’t impose any sort of application separation from the hardware. You can throw a random I2C_SendReceive() function in anywhere you’d like.
In Linux, there is a hard separation between userspace calls and the underlying hardware driver code. One key advantage of this is how easy it is to move from one hardware platform to another; it’s not uncommon to only have to change a couple of lines of code to specify the new device names when porting your code.
Yes, you can poke GPIO pins, perform I2C transactions, and fire off SPI messages from userspace in Linux, and there are some good reasons to use these tools during diagnosing and debugging. Plus, if you’re implementing a custom I2C peripheral device on a microcontroller, and there’s very little configuration to be done, it may seem silly to write a kernel driver whose only job is to expose a character device that basically passes on whatever data directly to the I2C device you’ve built.
But if you’re interfacing with off-the-shelf displays, accelerometers, IMUs, light sensors, pressure sensors, temperature sensors, ADCs, DACs, and basically anything else you’d toss on an I2C or SPI bus, Linux already has built-in support for this hardware that you can flip on when building your kernel and configure in your DTS file.
Developer Availability and Cost
When you combine all these challenges together, you can see that building out bare-metal C code is challenging (and thus expensive). If you want to be able to staff your shop with lesser-experienced developers who come from web-programming code schools or otherwise have only basic computer science backgrounds, you’ll need an architecture that’s easier to develop on.
This is especially true when the majority of the project is hardware-agnostic application code, and only a minor part of the project is low-level hardware interfacing.
Why shouldn’t you Linux?
There are lots of good reasons not to build your embedded system around Linux:
Sleep-mode power consumption. First, the good news: active mode power consumption of application processors is quite good when compared to microcontrollers. These parts tend to be built on smaller process nodes, so you get more megahertz for your ampere than the larger processes used for Cortex-M devices. Unfortunately, embedded Linux devices have a battery life that’s measured in hours or days, not months or years.
Modern low-power microcontrollers have a sleep-mode current consumption in the order of 1 μA — and that figure includes SRAM retention and usually even a low-power RTC oscillator running. Low-duty-cycle applications (like a sensor that logs a data point every hour) can run off a watch battery for a decade.
Application processors, however, can use 300 times as much power while asleep (that leaky 40 nm process has to catch up with us eventually!), but even that pales in comparison to the SDRAM, which can eat through 10 mA (yes mA, not μA) or more in self-refresh mode. Sure, you can suspend-to-flash (hibernate), but that’s only an option if you don’t need responsive wake-up.
Even companies like Apple can’t get around these fundamental limitations: compare the 18-hour battery life of the Apple Watch (which uses an application processor) to the 10-day life of the Pebble (which uses an STM32 microcontroller with a battery half the size of the Apple Watch).
Boot time. Embedded Linux systems can take several seconds to boot up, which is orders of magnitude longer than a microcontroller’s start-up time. Alright, to be fair, this is a bit of an apples-to-oranges comparison: if you were to start initializing tons of external peripherals, mount a filesystem, and initialize a large application in an RTOS on a microcontroller, it could take several seconds to boot up as well. While boot time is a culmination of tons of different components that can all be tweaked and tuned, the fundamental limit is caused by application processors’ inability to execute code from external flash memory; they must copy it into RAM first ((unless you’re running an XIP kernel)).
Responsiveness. By default, Linux’s scheduler and resource system are full of unbounded latencies that under weird and improbable scenarios may take a long time to resolve (or may actually never resolve). Have you ever seen your mouse lock up for 3 seconds randomly? There you go. If you’re building a ventilator with Linux, think carefully about that. To combat this, there’s been a PREEMPT_RT patch for some time that turns Linux into a real-time operating system with a scheduler that can basically preempt anything to make sure a hard-real-time task gets a chance to run.
Also, when many people think they need a hard-real-time kernel, they really just want their code to be low-jitter. Coming from Microcontrollerland, it feels like a 1000 MHz processor should be able to bit-bang something like a 50 kHz square wave consistently, but you would be wrong. The Linux scheduler is going to give you something on the order of ±10 µs of jitter for interrupts, not the ±10 ns jitter you’re used to on microcontrollers. This can be remedied too, though: while Linux gobbles up all the normal ARM interrupt vectors, it doesn’t touch FIQ, so you can write custom FIQ handlers that execute completely outside of kernel space.
Honestly, in practice, it’s much more common to just delegate these tasks to a separate microcontroller. Some of the parts reviewed here even include a built-in microcontroller co-processor designed for controls-oriented tasks, and it’s also pretty common to just solder down a $1 microcontroller and talk to it over SPI or I2C.
Design Workflow
The first step is to architect your system. This is hard to do unless what you’re building is trivial or you have a lot of experience, so you’ll probably start by buying some reference hardware, trying it out to see if it can do what you’re trying to do (both in terms of hardware and software), and then using that as a jumping-off point for your own designs.
I want to note that many designers focus too heavily on the hardware peripheral selection of the reference platform when architecting their system, and don’t spend enough time thinking about software early on. Just because your 500 MHz Cortex-A5 supports a parallel camera sensor interface doesn’t mean you’ll be able to forward-prop images through your custom SegNet implementation at 30 fps, and many parts reviewed here with dual Ethernet MACs would struggle to run even a modest web app.
Figuring out system requirements for your software frameworks can be rather unintuitive. For example, doing a multi-touch-capable finger-painting app in Qt 5 is actually much less of a resource hog than running a simple backend server for a web app written in a modern stack using a JIT-compiled language. Many developers familiar with traditional Linux server/desktop development assume they’ll just throw a .NET Core web app on their rootfs and call it a day — only to discover that they’ve completely run out of RAM, or their app takes more than five minutes to launch, or they discover that Node.js can’t even be compiled for the ARM9 processor they’ve been designing around.
The best advice I have is to simply try to run the software you’re interested in using on target hardware and try to characterize the performance as much as possible. Here are some guidelines for where to begin:
- Slower ARM9 cores are for simple headless gadgets written in C/C++. Yes, you can run basic, animation-free low-resolution touch linuxfb apps with these, but blending and other advanced 2D graphics technology can really bog things down. And yes, you can run very simple Python scripts, but in my testing, even a “Hello, World!” Flask app took 38 seconds from launch to actually spitting out a web page to my browser on a 300 MHz ARM9. Yes, obviously once the Python file was compiled, it was much faster, but you should primarily be serving up static content using lightweight HTTP servers whenever possible. And, no, you can’t even compile Node.JS or .NET Core for these architectures. These also tend to boot from small-capacity SPI flash chips, which limits your framework choices.
- Mid-range 500-1000 MHz Cortex-A-series systems can start to support interpreted / JIT-compiled languages better, but make sure you have plenty of RAM — 128 MB is really the bare minimum to consider. These have no issues running simple C/C++ touch-based GUIs running directly on a framebuffer but can stumble if you want to do lots of SVG rendering, pinch/zoom gestures, and any other canvas work.
- Multi-core 1+ GHz Cortex-A parts with 256 MB of RAM or more will begin to support desktop/server-like deployments. With large eMMC storage (4 GB or more), decent 2D graphics acceleration (or even 3D acceleration on some parts), you can build up complex interactive touchscreen apps using native C/C++ programming, and if the app is simple enough and you have sufficient RAM, potentially using an HTML/JS/CSS-based rendering engine. If you’re building an Internet-enabled device, you should have no issues doing the bulk of your development in Node.js, .NET Core, or Python if you prefer that over C/C++.
What about a Raspberry Pi?
I know that there are lots of people — especially hobbyists but even professional engineers — who have gotten to this point in the article and are thinking, “I do all my embedded Linux development with Raspberry Pi boards — why do I need to read this?” Yes, Raspberry Pi single-board computers, on the surface, look similar to some of these parts: they run Linux, you can attach displays to them, do networking, and they have USB, GPIO, I2C, and SPI signals available.
And for what it’s worth, the BCM2711 mounted on the Pi 4 is a beast of a processor and would easily best any part in this review on that measure. Dig a bit deeper, though: this processor has video decoding and graphics acceleration, but not even a single ADC input. It has built-in HDMI transmitters that can drive dual 4k displays, but just two PWM channels. This is a processor that was custom-made, from the ground up, to go into smart TVs and set-top boxes — it’s not a general-purpose embedded Linux application processor, so it isn’t generally suited for embedded Linux work.
It might be the perfect processor for your particular project, but it probably isn’t; forcing yourself to use a Pi early in the design process will over-constrain things. Yes, there are always workarounds to the aforementioned shortcomings — like I2C-interfaced PWM chips, SPI-interfaced ADCs, or LCD modules with HDMI receivers — but they involve external hardware that adds power, bulk, and cost. If you’re building a quantity-of-one project and you don’t care about these things, then maybe the Pi is the right choice for the job, but if you’re prototyping a real product that’s going to go into production someday, you’ll want to look at the entire landscape before deciding what’s best.
A note about peripherals
This article is all about getting an embedded application processor booting Linux — not building an entire embedded system. If you’re considering running Linux in an embedded design, you likely have some combination of Bluetooth, WiFi, Ethernet, TFT touch screen, audio, camera, or low-power RF transceiver work going on.
If you’re coming from the MCU world, you’ll have a lot of catching up to do in these areas, since the interfaces (and even architectural strategies) are quite different. For example, while single-chip WiFi/BT MCUs are common, very few application processors have integrated WiFi/BT, so you’ll typically use external SDIO- or USB-interfaced chipsets. Your SPI-interfaced ILI9341 TFTs will often be replaced with parallel RGB or MIPI models. And instead of burping out tones with your MCU’s 12-bit DAC, you’ll be wiring up I2S audio CODECs to your processor.

Hardware Workflow
Processor vendors vigorously encourage reference design modification and reuse for customer designs. I think most professional engineers are most concerned with getting Rev A hardware that boots up than playing around with optimization, so many custom Linux boards I see are spitting images of off-the-shelf EVKs.
But depending on the complexity of your project, this can become downright absurd. If you need the massive amount of RAM that some EVKs come with, and your design uses the same sorts of large parallel display and camera interfaces, audio codecs, and networking interfaces on the EVK, then it may be reasonable to use this as your base with little modification. However, using a 10-layer stack-up on your simple IoT gateway — just because that’s what the ref design used — is probably not something I’d throw in my portfolio to reflect a shining moment of ingenuity.
People forget that these EVKs are built at substantially higher volumes than prototype hardware is; I often have to explain to inexperienced project managers why it’s going to cost nearly $4000 to manufacture 5 prototypes of something you can buy for $56 each.
You may discover that it’s worth the extra time to clean up the design a bit, simplify your stackup, and reduce your BOM — or just start from scratch. All of the boards I built up for this review were designed in a few days and easily hand-assembled with low-cost hot-plate / hot-air / pencil soldering in a few hours onto cheap 4-layer PCBs from JLC. Even including the cost of assembly labor, it would be hard to spend more than a few hundred bucks on a round of prototypes so long as your design doesn’t have a ton of extraneous circuitry.
If you’re just going to copy the reference design files, the nitty-gritty details won’t be important. But if you’re going to start designing from-scratch boards around these parts, you’re going to notice some major differences from designing around microcontrollers.

BGA Packages
Most of the parts in this review come in BGA packages, so we should talk a little bit about this. These seem to make less-experienced engineers nervous — both during layout and prototype assembly. As you would expect, more-experienced engineers are more than happy to gatekeep and discourage less-experienced engineers from using these parts, but actually, I think BGAs are much easier to design around than high-pin-count ultra-fine-pitch QFPs, which are usually your only other packaging option.
The standard 0.8mm-pitch BGAs that mostly make up this review have a coarse-enough pitch to allow a single trace to pass between two adjacent balls, as well as allowing a via to be placed in the middle of a 4-ball grid with enough room between adjacent vias to allow a track to go between them. This is illustrated in the image above on the left: notice that the inner-most signals on the blue (bottom) layer escape the BGA package by traveling between the vias used to escape the outer-most signals on the blue layer.
In general, you can escape 4 rows of signals on a 0.8mm-pitch BGA with this strategy: the first two rows of signals from the BGA can be escaped on the component-side layer, while the next two rows of signals must be escaped on a second layer. If you need to escape more rows of signals, you’d need additional layers. IC designers are acutely aware of that; if an IC is designed for a 4-layer board (with two signal layers and two power planes), only the outer 4 rows of balls will carry I/O signals. If they need to escape more signals, they can start selectively depopulating balls on the outside of the package — removing a single ball gives space for three or four signals to fit through.
For 0.65mm-pitch BGAs (top right), a via can still (barely) fit between four pins, but there’s not enough room for a signal to travel between adjacent vias; they’re just too close. That’s why almost all 0.65mm-pitch BGAs must have selective depopulations on the outside of the BGA. You can see the escape strategy in the image on the right is much less orderly — there are other constraints (diff pairs, random power nets, final signal destinations) that often muck this strategy up. I think the biggest annoyance with BGAs is that decoupling capacitors usually end up on the bottom of the board if you have to escape many of the signals, though you can squeeze them onto the top side if you bump up the number of layers on your board (many solder-down SOMs do this).
Hand-assembling PCBs with these BGAs on them is a breeze. Because 0.8mm-pitch BGAs have such a coarse pitch, placement accuracy isn’t particularly important, and I’ve never once detected a short-circuit on a board I’ve soldered. That’s a far cry from 0.4mm-pitch (or even 0.5mm-pitch) QFPs, which routinely have minor short-circuits here and there — mostly due to poor stencil alignment. I haven’t had issues soldering 0.65mm-pitch BGAs, either, but I feel like I have to be much more careful with them.
To actually solder the boards, if you have an electric cooktop (I like the Cuisineart ones), you can hot-plate solder boards with BGAs on them. I have a reflow oven, but I didn’t use it once during this review — instead, I hot-plate the top side of the board, flip it over, paste it up, place the passives on the back, and hit it with a bit of hot air. Personally, I wouldn’t use a hot-air gun to solder BGAs or other large components, but others do it all the time. The advantage to hot-plate soldering is that you can poke and nudge misbehaving parts into place during the reflow cycle. I also like to give my BGAs a small tap to force them to self-align if they weren’t already.
Multiple voltage domains
Microcontrollers are almost universally supplied with a single, fixed voltage (which might be regulated down internally), while most microprocessors have a minimum of three voltage domains that must be supplied by external regulators: I/O (usually 3.3V), core (usually 1.0-1.2V), and memory (fixed for each technology — 1.35V for DDR3L, 1.5V for old-school DDR3, 1.8V for DDR2, and 2.5V for DDR). There are often additional analog supplies, and some higher-performance parts might have six or more different voltages you have to supply.
While many entry-level parts can be powered by a few discrete LDOs or DC/DC converters, some parts have stringent power-sequencing requirements. Also, to minimize power consumption, many parts recommend using dynamic voltage scaling, where the core voltage is automatically lowered when the CPU idles and lowers its clock frequency.
These two points lead designers to I2C-interfaced PMIC (power management integrated circuit) chips that are specifically tailored to the processor’s voltage and sequencing requirements, and whose output voltages can be changed on the fly. These chips might integrate four or more DC/DC converters, plus several LDOs. Many include multiple DC inputs along with built-in lithium-ion battery charging. Coupled with the large inductors, capacitors, and multiple precision resistors some of these PMICs require, this added circuitry can explode your bill of materials (BOM) and board area.
Regardless of your voltage regulator choices, these parts gesticulate wildly in their power consumption, so you’ll need some basic PDN design ability to ensure you can supply the parts with the current they need when they need it. And while you won’t need to do any simulation or verification just to get things to boot, if things are marginal, expect EMC issues down the road that would not come up if you were working with simple microcontrollers.
Non-volatile storage
No commonly-used microprocessor has built-in flash memory, so you’re going to need to wire something up to the MPU to store your code and persistent data. If you’ve used parts from fabless companies who didn’t want to pay for flash IP, you’ve probably gotten used to soldering down an SPI NOR flash chip, programming your hex file to it, and moving on with your life. When using microprocessors, there are many more decisions to consider.

Most MPUs can boot from SPI NOR flash, SPI NAND flash, parallel, or MMC (for use with eMMC or MicroSD cards). Because of its organization, NOR flash memory has better read speeds but worse write speeds than NAND flash. SPI NOR flash memory is widely used for tiny systems with up to 16 MB of storage, but above that, SPI NAND and parallel-interfaced NOR and NAND flash become cheaper. Parallel-interfaced NOR flash used to be the ubiquitous boot media for embedded Linux devices, but I don’t see it deployed as much anymore — even though it can be found at sometimes half the price of SPI flash. My only explanation for its unpopularity is that no one likes wasting lots of I/O pins on parallel memory.
Above 1 GB, MMC is the dominant technology in use today. For development work, it’s especially hard to beat a MicroSD card — in low volumes they tend to be cheaper per gigabyte than anything else out there, and you can easily read and write to them without having to interact with the MPU’s USB bootloader; that’s why it was my boot media of choice on almost all platforms reviewed here. In production, you can easily switch to eMMC, which is, very loosely speaking, a solder-down version of a MicroSD card.
Booting
Back when parallel-interfaced flash memory was the only game in town, there was no need for boot ROMs: unlike SPI or MMC, these devices have address and data pins, so they are easily memory-mapped; indeed, older processors would simply start executing code straight out of parallel flash on reset.
That’s all changed though: modern application processors have boot ROM code baked into the chip to initialize the SPI, parallel, or SDIO interface, load a few pages out of flash memory into RAM, and start executing it. Some of these ROMs are quite fancy, actually, and can even load files stored inside a filesystem on an MMC device. When building embedded hardware around a part, you’ll have to pay close attention to how to configure this boot ROM.
While some microprocessors have a basic boot strategy that simply tries every possible flash memory interface in a specified order, others have extremely complicated (“flexible”?) boot options that must be configured through one-time-programmable fuses or GPIO bootstrap pins. And no, we’re not talking about one or two signals you need to handle: some parts have more than 30 different bootstrap signals that must be pulled high or low to get the part booting correctly.
Console UART
Unlike MCU-based designs, on an embedded Linux system, you absolutely, positively, must have a console UART available. Linux’s entire tracing architecture is built around logging messages to a console, as is the U-Boot bootloader.
That doesn’t mean you shouldn’t also have JTAG/SWD access, especially in the early stage of development when you’re bringing up your bootloader (otherwise you’ll be stuck with printf() calls). Having said that, if you actually have to break out your J-Link on your embedded Linux board, it probably means you’re having a really bad day. While you can attach a debugger to an MPU, getting everything set up correctly is extremely clunky when compared to debugging an MCU. Prepare to relocate symbol tables as your code transitions from SRAM to main DRAM memory. It’s not uncommon to have to muck around with other registers, too (like forcing your CPU out of Thumb mode). And on top of that, I’ve found that some U-Boot ports remux the JTAG pins (either due to alternate functionality or to save power), and the JTAG chains on some parts are quite complex and require using less-commonly used pins and features of the interface. Oh, and since you have an underlying Boot ROM that executes first, JTAG adapters can screw that up, too.

Sidebar: Gatekeepers and the Myth of DDR Routing Complexity
If you start searching around the Internet, you’ll stumble upon a lot of posts from people asking about routing an SDRAM memory bus, only to be discouraged by “experts” lecturing them on how unbelievably complex memory routing is and how you need a minimum 6-layer stack-up and super precise length-tuning and controlled impedances and $200,000 in equipment to get a design working.
That’s utter bullshit. In the grand scheme of things, routing memory is, at worst, a bit tedious. Once you’ve had some practice, it should take about an hour or so to route a 16-bit-wide single-chip DDR3 memory bus, so I’d hardly call it an insurmountable challenge. It’s worth investing a bit of time to learn about it since it will give you immense design flexibility when architecting your system (since you won’t be beholden to expensive SoMs or SiP-packaged parts).
Let’s get one thing straight: I’m not talking about laying out a 64-bit-wide quad-bank memory bus with 16 chips on an 8-layer stack-up. Instead, we’re focused on a single 16-bit-wide memory chip routed point-to-point with the CPU. This is the layout strategy you’d use with all the parts in this review, and it is drastically simpler than multi-chip layouts — no address bus terminations, complex T-topology routes, or fly-by write-leveling to worry about. And with modern dual-die DRAM packages, you can get up to 2 GB capacity in a single DDR3L chip. In exchange for the markup you’ll pay for the dual-die chips, you’ll end up with much easier PCB routing.
Length Tuning
When most people think of DDR routing, length-tuning is the first thing that comes to mind. If you use a decent PCB design package, setting up length-tuning rules and laying down meandered routes is so trivial to do that most designers don’t think anything of it — they just go ahead and length-match everything that’s relatively high-speed — SDRAM, SDIO, parallel CSI / LCD, etc. Other than adding a bit of design time, there’s no reason not to maximize your timing margins, so this makes sense.
But what if you’re stuck in a crappy software package, manually exporting spreadsheets of track lengths, manually determining matching constraints, and — gasp — maybe even manually creating meanders? Just how important is length-matching? Can you get by without it?
Most microprocessors reviewed here top out at DDR3-800, which has a bit period of 1250 ps. Slow DDR3-800 memory might have a data setup time of up to 165 ps at AC135 levels, and a hold time of 150 ps. There’s also a worst-case skew of 200 ps. Let’s assume our microprocessor has the same specs. That means we have 200 ps of skew from our processor + 200 ps of skew from our DRAM chip + 165 ps setup time + 150 ps of hold time = 715 ps total. That leaves a margin of 535 ps (more than 3500 mil!) for PCB length mismatching.

Are our assumptions about the MPU’s memory controller valid? Who knows. One issue I ran into is that there’s a nebulous cloud surrounding the DDR controllers on many application processors. Take the i.MX 6UL as an example: I discovered multiple posts where people add up worst-case timing parameters in the datasheet, only to end up with practically no timing margin. These official datasheet numbers seem to be pulled out of thin air — so much so that NXP literally removed the entire DDR section in their datasheet and replaced it with a boiler-plate explanation telling users to follow the “hardware design guidelines.” Texas Instruments and ST also lack memory controller timing information in their documentation — again, referring users to stringent hardware design rules. ((Rockchip and Allwinner don’t specify any sort of timing data or length-tuning guidelines for their processors at all.))
How stringent are these rules? Almost all of these companies recommend a ±25-mil match on each byte group. Assuming 150 ps/cm propagation delay, that’s ±3.175 ps — only 0.25% of that 1250ps DDR3-800 bit period. That’s absolutely nuts. Imagine if you were told to ensure your breadboard wires were all within half an inch in length of each other before wiring up your Arduino SPI sensor project — that’s the equivalent timing margin we’re talking about.
To settle this, I empirically tested two DDR3-800 designs — one with and one without length tuning — and they performed identically. In neither case was I ever able to get a single bit error, even after thousands of iterations of memory stress-tests. Yes, that doesn’t prove that the design would run for 24/7/365 without a bit error, but it’s definitely a start. Just to verify I wasn’t on the margin, or that this was only valid for one processor, I overclocked a second system’s memory controller by two times — running a DDR3-800 controller at DDR3-1600 speeds — and I was still unable to get a single bit error. In fact, all five of my discrete-SDRAM-based designs violated these length-matching guidelines and all five of them completed memory tests without issue, and in all my other testing, I never experienced a single crash or lock-up on any of these boards.
My take-away: length-tuning is easy if you have good CAD software, and there’s no reason not to spend an extra 30 minutes length-tuning things to maximize your timing budget. But if you use crappy CAD software or you’re rushing to get a prototype out the door, don’t sweat it — especially for Rev A.
More importantly, a corollary: if your design doesn’t work, length-tuning is probably the last thing you should be looking at. For starters, make sure you have all the pins connected properly — even if the failures appear intermittent. For example, accidentally swapping byte lane strobes / masks (like I’ve done) will cause 8-bit operations to fail without affecting 32-bit operations. Since the bulk of RAM accesses are 32-bit, things will appear to kinda-sorta work.

Signal Integrity
Instead of worrying about length-tuning, if a design is failing (either functionally or in the EMC test chamber), I would look first at power distribution and signal integrity. I threw together some HyperLynx simulations of various board designs with different routing strategies to illustrate some of this. I’m not an SI expert, and there are better resources online if you want to learn more practical techniques; for more theory, the books that everyone seems to recommend are by Howard Johnson: High Speed Digital Design: A Handbook of Black Magic and High Speed Signal Propagation: Advanced Black Magic, though I’d also add Henry Ott’s Electromagnetic Compatibility Engineering book to that list.
Ideally, every signal’s source impedance, trace impedance, and load impedance would match. This is especially important as a trace’s length starts to approach the wavelength of the signal (I think the rule of thumb is 1/20th the wavelength), which will definitely be true for 400 MHz and faster DDR layouts.
Using a proper PCB stack-up (usually a ~0.1mm prepreg will result in a close-to-50-ohm impedance for a 5mil-wide trace) is your first line of defense against impedance issues, and is usually sufficient for getting things working well enough to avoid simulation / refinement.
For the data groups, DDR3 uses on-die termination (ODT), configurable for 40, 60, or 120 ohm on memory chips (and usually the same or similar on the CPU) along with adjustable output impedance drivers. ODT is only enabled on the receiver’s end, so depending on whether you’re writing data or reading data, ODT will either be enabled on the memory chip, or on the CPU.
For simple point-to-point routing, don’t worry too much about ODT settings. As can be seen in the above eye diagram, the difference between 33-ohm and 80-ohm ODT terminations on a CPU reading from DRAM is perceivable, but both are well within AC175 levels (the most stringent voltage levels in the DDR3 spec). The BSP for your processor will initialize the DRAM controller with default settings that will likely work just fine.

The biggest source of EMC issues related to DDR3 is likely going to come from your address bus. DDR3 uses a one-way address bus (the CPU is always the transmitter and the memory chip is always the receiver), and DDR memory chips do not have on-chip termination for these signals. Theoretically, they should be terminated to VTT (a voltage derived from VDDQ/2) with resistors placed next to the DDR memory chip. On large fly-by buses with multiple memory chips, you’ll see these VTT termination resistors next to the last chip on the bus. The resistors absorb the EM wave propagating from the MPU which reduces the reflections back along the transmission line that all the memory chips would see as voltage fluctuations. On small point-to-point designs, the length of the address bus is usually so short that there’s no need to terminate. If you run into EMC issues, consider software fixes first, like using slower slew-rate settings or increasing the output impedance to soften up your signals a bit.

Another source of SI issues is cross-coupling between traces. To reduce cross-talk, you can put plenty of space between traces — three times the width (3S) is a standard rule of thumb. I sound like a broken record, but again, don’t be too dogmatic about this unless you’re failing tests, as the lengths involved with routing a single chip are so short. The above figure illustrates the routing of a DDR bus with no length-tuning but with ample space between traces. Note the eye diagram (below) shows much better signal integrity (at the expense of timing skew) than the first eye diagram presented in this section.

Pin Swapping
Because DDR memory doesn’t care about the order of the bits getting stored, you can swap individual bits — except the least-significant one if you’re using write-leveling — in each byte lane with no issues. Byte lanes themselves are also completely swappable. Having said that, since all the parts I reviewed are designed to work with a single x16-wide DDR chip (which has an industry-standard pinout), I found that most pins were already balled out reasonably well. Before you start swapping pins, make sure you’re not overlooking an obvious layout that the IC designers intended.
Recommendations
Instead of worrying about chatter you read on forums or what the HyperLynx salesperson is trying to spin, for simple point-to-point DDR designs, you shouldn’t have any issues if you follow these suggestions:
Pay attention to PCB stack-up. Use a 4-layer stack-up with thin prepreg (~0.1mm) to lower the impedance of your microstrips — this allows the traces to transfer more energy to the receiver. Those inner layers should be solid ground and DDR VDD planes respectively. Make sure there are no splits under the routes. If you’re nit-picky, pull back the outer-layer copper fills from these tracks so you don’t inadvertently create coplanar structures that will lower the impedance too much.
Avoid multiple DRAM chips. If you start adding extra DRAM chips, you’ll have to route your address/command signals with a fly-by topology (which requires terminating all those signals — yuck), or a T-topology (which requires additional routing complexity). Stick with 16-bit-wide SDRAM, and if you need more capacity, spend the extra money on a dual-die chip — you can get up to 2 GB of RAM in a single X16-wide dual-rank chip, which should be plenty for anything you’d throw at these CPUs.
Faster RAM makes routing easier. Even though our crappy processors reviewed here rarely can go past 400-533 MHz DDR speeds, using 800 or 933 MHz DDR chips will ease your timing budget. The reduced setup/hold times make address/command length-tuning almost entirely unnecessary, and the reduced skew even helps with the bidrectional data bus signals.
Software Workflow
Developing on an MCU is simple: install the vendor’s IDE, create a new project, and start programming/debugging. There might be some .c/.h files to include from a library you’d like to use, and rarely, a precompiled lib you’ll have to link against.
When building embedded Linux systems, we need to start by compiling all the off-the-shelf software we plan on running — the bootloader, kernel, and userspace libraries and applications. We’ll have to write and customize shell scripts and configuration files, and we’ll also often write applications from scratch. It’s really a totally different development process, so let’s talk about some prerequisites.
If you want to build a software image for a Linux system, you’ll need a Linux system. If you’re also the person designing the hardware, this is a bit of a catch-22 since most PCB designers work in Windows. While Windows Subsystem for Linux will run all the software you need to build an image for your board, WSL currently has no ability to pass through USB devices, so you won’t be able to use hardware debuggers (or even a USB microSD card reader) from within your Linux system. And since WSL2 is Hyper-V-based, once it’s enabled, you won’t be able to launch VMware, which uses its own hypervisor((Though a beta versions of VMWare will address this)).
Consequently, I recommend users skip over all the newfangled tech until it matures a bit more, and instead just spin up an old-school VMWare virtual machine and install Linux on it. In VMWare you can pass through your MicroSD card reader, debug probe, and even the device itself (which usually has a USB bootloader).
Building images is a computationally heavy and highly-parallel workload, so it benefits from large, high-wattage HEDT/server-grade multicore CPUs in your computer — make sure to pass as many cores through to your VM as possible. Compiling all the software for your target will also eat through storage quickly: I would allocate an absolute minimum of 200 GB if you anticipate juggling between a few large embedded Linux projects simultaneously.
While your specific project will likely call for much more software than this, these are the five components that go into every modern embedded Linux system((Yes, there are alternatives to these components, but the further you move away from the embedded Linux canon, the more you’ll find yourself on your own island, scratching your head trying to get things to work.)):
- A cross toolchain, usually GCC + glibc, which contains your compiler, binutils, and C library. This doesn’t actually go into your embedded Linux system, but rather is used to build the other components.
- U-boot, a bootloader that initializes your DRAM, console, and boot media, and then loads the Linux kernel into RAM and starts executing it.
- The Linux kernel itself, which manages memory, schedules processes, and interfaces with hardware and networks.
- Busybox, a single executable that contains core userspace components (init, sh, etc)
- a root filesystem, which contains the aforementioned userspace components, along with any loadable kernel modules you compiled, shared libraries, and configuration files.
As you’re reading through this, don’t get overwhelmed: if your hardware is reasonably close to an existing reference design or evaluation kit, someone has already gone to the trouble of creating default configurations for you for all of these components, and you can simply find and modify them. As an embedded Linux developer doing BSP work, you’ll spend way more time reading other people’s code and modifying it than you will be writing new software from scratch.
Cross Toolchain
Just like with microcontroller development, when working on embedded Linux projects, you’ll write and compile the software on your computer, then remotely test it on your target. When programming microcontrollers, you’d probably just use your vendor’s IDE, which comes with a cross toolchain — a toolchain designed to build software for one CPU architecture on a system running a different architecture. As an example, when programming an ATTiny1616, you’d use a version of GCC built to run on your x64 computer but designed to emit AVR code. With embedded Linux development, you’ll need a cross toolchain here, too (unless you’re one of the rare types coding on an ARM-based laptop or building an x64-powered embedded system).
When configuring your toolchain, there are two lightweight C libraries to consider — musl libc and uClibc-ng — which implement a subset of features of the full glibc, while being 1/5th the size. Most software compiles fine against them, so they’re a great choice when you don’t need the full libc features. Between the two of them, uClibc is the older project that tries to act more like glibc, while musl is a fresh rewrite that offers some pretty impressive stats, but is less compatible.
U-Boot
Unfortunately, our CPU’s boot ROM can’t directly load our kernel. Linux has to be invoked in a specific way to obtain boot arguments and a pointer to the device tree and initrd, and it also expects that main memory has already been initialized. Boot ROMs also don’t know how to initialize main memory, so we would have nowhere to store Linux. Also, boot ROMs tend to just load a few KB from flash at the most — not enough to house an entire kernel. So, we need a small program that the boot ROM can load that will initialize our main memory and then load the entire (usually-multi-megabyte) Linux kernel and then execute it.
The most popular bootloader for embedded systems, Das U-Boot, does all of that — but adds a ton of extra features. It has a fully interactive shell, scripting support, and USB/network booting.
If you’re using a tiny SPI flash chip for booting, you’ll probably store your kernel, device tree, and initrd / root filesystem at different offsets in raw flash — which U-Boot will gladly load into RAM and execute for you. But since it also has full filesystem support, so you could store your kernel and device tree as normal files on a partition of an SD card, eMMC device, or on a USB flash drive.
U-Boot has to know a lot of technical details about your system. There’s a dedicated board.c port for each supported platform that initializes clocks, DRAM, and relevant memory peripherals, along with initializing any important peripherals, like your UART console or a PMIC that might need to be configured properly before bringing the CPU up to full speed. Newer board ports often store at least some of this configuration information inside a Device Tree, which we’ll talk about later. Some of the DRAM configuration data is often autodetected, allowing you to change DRAM size and layout without altering the U-Boot port’s code for your processor ((If you have a DRAM layout on the margins of working, or you’re using a memory chip with very different timings than the one the port was built for, you may have to tune these values)). You configure what you want U-Boot to do by writing a script that tells it which device to initialize, which file/address to load into which memory address, and what boot arguments to pass along to Linux. While these can be hard-coded, you’ll often store these names and addresses as environmental variables (the boot script itself can be stored as a bootcmd environmental variable). So a large part of getting U-Boot working on a new board is working out the environment.
Linux Kernel
Here’s the headline act. Once U-Boot turns over the program counter to Linux, the kernel initializes itself, loads its own set of device drivers((Linux does not call into U-Boot drivers the way that an old PC operating system like DOS makes calls into BIOS functions.)) and other kernel modules, and calls your init program.
To get your board working, the necessary kernel hacking will usually be limited to enabling filesystems, network features, and device drivers — but there are more advanced options to control and tune the underlying functionality of the kernel.
Turning drivers on and off is easy, but actually configuring these drivers is where new developers get hung up. One big difference between embedded Linux and desktop Linux is that embedded Linux systems have to manually pass the hardware configuration information to Linux through a Device Tree file or platform data C code, since we don’t have EFI or ACPI or any of that desktop stuff that lets Linux auto-discover our hardware.
We need to tell Linux the addresses and configurations for all of our CPU’s fancy on-chip peripherals, and which kernel modules to load for each of them. You may think that’s part of the Linux port for our CPU, but in Linux’s eyes, even peripherals that are literally inside our processor — like LCD controllers, SPI interfaces, or ADCs — have nothing to do with the CPU, so they’re handled totally separately as device drivers stored in separate kernel modules.
And then there’s all the off-chip peripherals on our PCB. Sensors, displays, and basically all other non-USB devices need to be manually instantiated and configured. This is how we tell Linx that there’s an MPU6050 IMU attached to I2C0 with an address of 0x68, or an OV5640 image sensor attached to a MIPI D-PHY. Many device drivers have additional configuration information, like a prescalar factor, update rate, or interrupt pin use.
The old way of doing this was manually adding C structs to a platform_data C file for the board, but the modern way is with a Device Tree, which is a configuration file that describes every piece of hardware on the board in a weird quasi-C/JSONish syntax. Each logical piece of hardware is represented as a node that is nested under its parent bus/device; its node is adorned with any configuration parameters needed by the driver.
A DTS file is not compiled into the kernel, but rather, into a separate .dtb binary blob file that you have to deal with (save to your flash memory, configure u-boot to load, etc)((OK, I lied. You can actually append the DTB to the kernel so U-Boot doesn’t need to know about it. I see this done a lot with simple systems that boot from raw Flash devices.)). I think beginners have a reason to be frustrated at this system, since there’s basically two separate places you have to think about device drivers: Kconfig and your DTS file, and if these get out of sync, it can be frustrating to diagnose, since you won’t get a compilation error if your device tree contains nodes that there are no drivers for, or if your kernel is built with a driver that isn’t actually referenced for in the DTS file, or if you misspell a property or something (since all bindings are resolved at runtime).
BusyBox
Once Linux has finished initializing, it runs init. This is the first userspace program invoked on start-up. Our init program will likely want to run some shell scripts, so it’d be nice to have a sh we can invoke. Those scripts might touch or echo or cat things. It looks like we’re going to need to put a lot of userspace software on our root filesystem just to get things to boot — now imagine we want to actually login (getty), list a directory (ls), configure a network (ifconfig), or edit a text file (vi, emacs, nano, vim, flamewars ensue).
Rather than compiling all of these separately, BusyBox collects small, light-weight versions of these programs (plus hundreds more) into a single source tree that we can compile and link into a single binary executable. We then create symbolic links to BusyBox named after all these separate tools, then when we call them on the command line to start up, BusyBox determines how it was invoked and runs the appropriate command. Genius!
BusyBox configuration is obvious and uses the same Kconfig-based system that Linux and U-Boot use. You simply tell it which packages (and options) you wish to build the binary image with. There’s not much else to say — though a minor “gotcha” for new users is that the lightweight versions of these tools often have fewer features and don’t always support the same syntax/arguments.
Root Filesystems
Linux requires a root filesystem; it needs to know where the root filesystem is and what filesystem format it uses, and this parameter is part of its boot arguments.
Many simple devices don’t need to persist data across reboot cycles, so they can just copy the entire rootfs into RAM before booting (this is called initrd). But what if you want to write data back to your root filesystem? Other than MMC, all embedded flash memory is unmanaged — it is up to the host to work around bad blocks that develop over time from repeated write/erase cycles. Most normal filesystems are not optimized for this workload, so there are specialized filesystems that target flash memory; the three most popular are JFFS2, YAFFS2, and UBIFS. These filesystems have vastly different performance envelopes, but for what it’s worth, I generally see UBIFS deployed more on higher-end devices and YAFFS2 and JFFS2 deployed on smaller systems.
MMC devices have a built-in flash memory controller that abstracts away the details of the underlying flash memory and handles bad blocks for you. These managed flash devices are much simpler to use in designs since they use traditional partition tables and filesystems — they can be used just like the hard drives and SSDs in your PC.
Yocto & Buildroot
If the preceding section made you dizzy, don’t worry: there’s really no reason to hand-configure and hand-compile all of that stuff individually. Instead, everyone uses build systems — the two big ones being Yocto and Buildroot — to automatically fetch and compile a full toolchain, U-Boot, Linux kernel, BusyBox, plus thousands of other packages you may wish, and install everything into a target filesystem ready to deploy to your hardware.
Even more importantly, these build systems contain default configurations for the vendor- and community-developed dev boards that we use to test out these CPUs and base our hardware from. These default configurations are a real life-saver.
Yes, on their own, both U-Boot and Linux have defconfigs that do the heavy lifting: For example, by using a U-Boot defconfig, someone has already done the work for you in configuring U-Boot to initialize a specific boot media and boot off it (including setting up the SPL code, activating the activating the appropriate peripherals, and writing a reasonable U-Boot environment and boot script).
But the build system default configurations go a step further and integrate all these pieces together. For example, assume you want your system to boot off a MicroSD card, with U-Boot written directly at the beginning of the card, followed by a FAT32 partition containing your kernel and device tree, and an ext4 root filesystem partition. U-Boot’s defconfig will spit out the appropriate bin file to write to the SD card, and Linux’s defconfig will spit out the appropriate vmlinuz file, but it’s the build system itself that will create a MicroSD image, write U-Boot to it, create the partition scheme, format the filesystems, and copy the appropriate files to them. Out will pop an “image.sdcard” file that you can write to a MicroSD card.
Almost every commercially-available dev board has at least unofficial support in either or both Buildroot or Yocto, so you can build a functioning image with usually one or two commands.
These two build environments are absolutely, positively, diametrically opposed to each other in spirit, implementation, features, origin story, and industry support. Seriously, I have never found two software projects that do the same thing in such totally different ways. Let’s dive in.
Buildroot
Buildroot started as a bunch of Makefiles strung together to test uClibc against a pile of different commonly-used applications to help squash bugs in the library. Today, the infrastructure is the same, but it’s evolved to be the easiest way to build embedded Linux images.
By using the same Kconfig system used in Linux, U-Boot, and BusyBox, you configure everything — the target architecture, the toolchain, Linux, U-Boot, target packages, and overall system configuration — by simply running make menuconfig. It ships with tons of canned defconfigs that let you get a working image for your dev board by loading that config and running make. For example, make raspberrypi3_defconfig && make will spit out an SD card image you can use to boot your Pi off of.
Buildroot can also pass you off to the respective Kconfigs for Linux, U-Boot, or BusyBox — for example, running make linux-menuconfig will invoke the Linux menuconfig editor from within the Buildroot directory. I think beginners will struggle to know what is a Buildroot option and what is a Linux kernel or U-Boot option, so be sure to check in different places.
Buildroot is distributed as a single source tree, licensed as GPL v2. To properly add your own hardware, you’d add a defconfig file and board folder with the relevant bits in it (these can vary quite a bit, but often include U-Boot scripts, maybe some patches, or sometimes nothing at all). While they admit it is not strictly necessary, Buildroot’s documentation notes “the general view of the Buildroot developers is that you should release the Buildroot source code along with the source code of other packages when releasing a product that contains GPL-licensed software.” I know that many products (3D printers, smart thermostats, test equipment) use Buildroot, yet none of these are found in the officially supported configurations, so I can’t imagine people generally follow through with the above sentiment; the only defconfigs I see are for development boards.
And, honestly, for run-and-gun projects, you probably won’t even bother creating an official board or defconfig — you’ll just hack at the existing ones. We can do this because Buildroot is crafty in lots of good ways designed to make it easy to make stuff work. For starters, most of the relevant settings are part of the defconfig file that can easily be modified and saved — for very simple projects, you won’t have to make further modifications. Think about toggling on a device driver: in Buildroot, you can invoke Linux’s menuconfig, modify things, save that config back to disk, and update your Buildroot config file to use your local Linux config, rather the one in the source tree. Buildroot knows how to pass out-of-tree DTS files to the compiler, so you can create a fresh DTS file for your board without even having to put it in your kernel source tree or create a machine or anything. And if you do need to modify the kernel source, you can hardwire the build process to bypass the specified kernel and use an on-disk one (which is great when doing active development).
The chink in the armor is that Buildroot is brain-dead at incremental builds. For example, if you load your defconfig, make, and then add a package, you can probably just run make again and everything will work. But if you change a package option, running make won’t automatically pick that up, and if there are other packages that need to be rebuilt as a result of that upstream dependency, Buildroot won’t rebuild those either. You can use the make [package]-rebuild target, but you have to understand the dependency graph connecting your different packages. Half the time, you’ll probably just give up and do make clean && make ((Just remember to save your Linux, U-Boot, and BusyBox configuration modifications first, since they’ll get wiped out.)) and end up rebuilding everything from scratch, which, even with the compiler cache enabled, takes forever. Honestly, Buildroot is the principal reason that I upgraded to a Threadripper 3970X during this project.
Yocto
Yocto is totally the opposite. Buildroot was created as a scrappy project by the BusyBox/uClibc folks. Yocto is a giant industry-sponsored project with tons of different moving parts. You will see this build system referred to as Yocto, OpenEmbedded, and Poky, and I did some reading before publishing this article because I never really understood the relationship. I think the first is the overall head project, the second is the set of base packages, and the third is the… nope, I still don’t know. Someone complain in the comments and clarify, please.
Here’s what I do know: Yocto uses a Python-based build system (BitBake) that parses “recipe” files to execute tasks. Recipes can inherit from other recipes, overriding or appending tasks, variables, etc. There’s a separate “Machine” configuration system that’s closely related. Recipes are grouped into categories and layers.
There are many layers in the official Yocto repos. Layers can be licensed and distributed separately, so many companies maintain their own “Yocto layers” (e.g., meta-atmel), and the big players actually maintain their own distribution that they build with Yocto. TI’s ProcessorSDK is built using their Arago Project infrastructure, which is built on top of Yocto. The same goes for ST’s OpenSTLinux Distribution. Even though Yocto distributors make heavy use of Google’s repo tool, getting a set of all the layers necessary to build an image can be tedious, and it’s not uncommon for me to run into strange bugs that occur when different vendors’ layers collide.
While Buildroot uses Kconfig (allowing you to use menuconfig), Yocto uses config files spread out all over the place: you definitely need a text editor with a built-in file browser, and since everything is configuration-file-based, instead of a GUI like menuconfig, you’ll need to have constant documentation up on your screen to understand the parameter names and values. It’s an extremely steep learning curve.
However, if you just want to build an image for an existing board, things couldn’t be easier: there’s a single environmental variable, MACHINE, that you must set to match your target. Then, you BitBake the name of the image you want to build (e.g., bitbake core-image-minimal) and you’re off to the races.
But here’s where Yocto falls flat for me as a hardware person: it has absolutely no interest in helping you build images for the shiny new custom board you just made. It is not a tool for quickly hacking together a kernel/U-Boot/rootfs during the early stages of prototyping (say, during this entire blog project). It wasn’t designed for that, so architectural decisions they made ensure it will never be that. It’s written in a very software-engineery way that values encapsulation, abstraction, and generality above all else. It’s not hard-coded to know anything, so you have to modify tons of recipes and create clunky file overlays whenever you want to do even the simplest stuff. It doesn’t know what DTS files are, so it doesn’t have a “quick trick” to compile Linux with a custom one. Even seemingly mundane things — like using menuconfig to modify your kernel’s config file and save that back somewhere so it doesn’t get wiped out — become ridiculous tasks. Just read through Section 1 of this Yocto guide to see what it takes to accomplish the equivalent of Buildroot’s make linux-savedefconfig((Alright, to be fair: many kernel recipes are set up with a hardcoded defconfig file inside the recipe folder itself, so you can often just manually copy over that file with a generated defconfig file from your kernel build directory — but this relies on your kernel recipe being set up this way)). Instead, if I plan on having to modify kernel configurations or DTS files, I usually resort to the nuclear option: copy the entire kernel somewhere else and then set the kernel recipe’s SRC_URI to that.
Yocto is a great tool to use once you have a working kernel and U-Boot, and you’re focused on sculpting the rest of your rootfs. Yocto is much smarter at incremental builds than Buildroot — if you change a package configuration and rebuild it, when you rebuild your image, Yocto will intelligently rebuild any other packages necessary. Yocto also lets you easily switch between machines, and organizes package builds into those specific to a machine (like the kernel), those specific to an architecture (like, say, Qt5), and those that are universal (like a PNG icon pack). Since it doesn’t rebuild packages unecessarily, this has the effect of letting you quickly switch between machines that share an instruction set (say ARMv7) without having to rebuild a bunch of packages.
It may not seem like a big distinction when you’re getting started, but Yocto builds a Linux distribution, while Buildroot builds a system image. Yocto knows what each software component is and how those components depend on each other. As a result, Yocto can build a package feed for your platform, allowing you to remotely install and update software on your embedded product just as you would a desktop or server Linux instance. That’s why Yocto thinks of itself not as a Linux distribution, but as a tool to build Linux distributions. Whether you use that feature or not is a complicated decision — I think most embedded Linux engineers prefer to do whole-image updates at once to ensure there’s no chance of something screwy going on. But if you’re building a huge project with a 500 MB root filesystem, pushing images like that down the tube can eat through a lot of bandwidth (and annoy customers with “Downloading….” progress bars).
When I started this project, I sort of expected to bounce between Buildroot and Yocto, but I ended up using Buildroot exclusively (even though I had much more experience with Yocto), and it was definitely the right choice. Yes, it was ridiculous: I had 10 different processors I was building images for, so I had 10 different copies of buildroot, each configured for a separate board. I bet 90% of the binary junk in these folders was identical. Yocto would have enabled me to switch between these machines quickly. In the end, though, Yocto is simply not designed to help you bring up new hardware. You can do it, but it’s much more painful.
The Contenders
I wanted to focus on entry-level CPUs — these parts tend to run at up to 1 GHz and use either in-package SDRAM or a single 16-bit-wide DDR3 SDRAM chip. These are the sorts of chips used in IoT products like upscale WiFi-enabled devices, smart home hubs, and edge gateways. You’ll also see them in some HMI applications like high-end desktop 3D printers and test equipment.
Here’s a brief run-down of each CPU I reviewed:
- Allwinner F1C200s: a 400 MHz ARM9 SIP with 64 MB (or 32 MB for the F1C100s) of DDR SDRAM, packaged in an 88-pin QFN. Suitable for basic HMI applications with a parallel LCD interface, built-in audio codec, USB port, one SDIO interface, and little else.
- Nuvoton NUC980: 300 MHz ARM9 SIP available in a variety of QFP packages and memory configurations. No RGB LCD controller, but has an oddly large number of USB ports and controls-friendly peripherals.
- Microchip SAM9X60 SIP: 600 MHz ARM9 SIP with up to 128 MB of SDRAM. Typical peripheral set of mainstream, industrial-friendly ARM SoCs.
- Microchip SAMA5D27 SIP: 500 MHz Cortex-A5 (the only one out there offered by a major manufacturer) with up to 256 MB of DDR2 SDRAM built-in. Tons of peripherals and smartly-multiplexed I/O pins.
- Allwinner V3s: 1 GHz Cortex-A7 in a SIP with 64 MB of RAM. Has the same fixings as the F1C200s, plus an extra SDIO interface and, most unusually, a built-in Ethernet PHY — all packaged in a 128-pin QFP.
- Allwinner A33: Quad-core 1.2 GHz Cortex-A9 with an integrated GPU, plus support for driving MIPI and LVDS displays directly. Strangely, no Ethernet support.
- NXP i.MX 6ULx: Large cohort of mainstream Cortex-A7 chips available with tons of speed grades up to 900 MHz and typical peripheral permutations across the UL, ULL, and ULZ subfamilies.
- Texas Instruments Sitara AM335x and AMIC110: Wide-reaching family of 300-1000 MHz Cortex-A7 parts with typical peripherals, save for the integrated GPU found on the highest-end parts.
- STMicroelectronics STM32MP1: New for this year, a family of Cortex-A7 parts sporting up to dual 800 MHz cores with an additional 200 MHz Cortex-M4 and GPU acceleration. Features a controls-heavy peripheral set and MIPI display support.
- Rockchip RK3308: A quad-core 1.3 GHz Cortex-A35 that’s a much newer design than any of the other parts reviewed. Tailor-made for smart speakers, this part has enough peripherals to cover general embedded Linux work while being one of the easiest Rockchip parts to design around.
From the above list, it’s easy to see that even in this “entry level” category, there’s tons of variation — from 64-pin ARM9s running at 300 MHz, all the way up to multi-core chips with GPU acceleration stuffed in BGA packages that have 300 pins or more.
The Microchip, NXP, ST, and TI parts are what I would consider general-purpose MPUs: designed to drop into a wide variety of industrial and consumer connectivity, control, and graphical applications. They have 10/100 ethernet MACs (obviously requiring external PHYs to use), a parallel RGB LCD interface, a parallel camera sensor interface, two SDIO interfaces (typically one used for storage and the other for WiFi), and up to a dozen each of UARTs, SPI, I2C, and I2S interfaces. They often have extensive timers and a dozen or so ADC channels. These parts are also packaged in large BGAs that ball-out 100 or more I/O pins that enable you to build larger, more complicated systems.
The Nuvoton NUC980 has many of the same features of these general-purpose MPUs (in terms of communication peripherals, timers, and ADC channels), but it leans heavily toward IoT applications: it lacks a parallel RGB interface, its SDK targets booting off small and slow SPI flash, and it’s…. well… just plain slow.
On the other hand, the Allwinner and Rockchip parts are much more purpose-built for consumer goods — usually very specific consumer goods. With a built-in Ethernet PHY and a parallel and MIPI camera interface, the V3s is obviously designed as an IP camera. The F1C100s — a part with no Ethernet but with a hardware video decoder — is built for low-cost video playback applications. The A33 — with LVDS / MIPI display support, GPU acceleration, and no Ethernet — is for entry-level Android tablets. None of these parts have more than a couple UART, I2C, or SPI interfaces, and you might get a single ADC input and PWM channel on them, with no real timer resources available. But they all have built-in audio codecs — a feature not found anywhere else — along with hardware video decoding (and, in some cases, encoding). Unfortunately, with Allwinner, you always have to put a big asterisk by these hardware peripherals, since many of them will only work when using the old kernel that Allwinner distributes — along with proprietary media encoding/decoding libraries. Mainline Linux support will be discussed more for each part separately.
Invasion of the SIPs
From a hardware design perspective, one of the takeaways from this article should be that SIPs — System-in-Package ICs that bundle an application processor along with SDRAM in a single chip — are becoming commonplace, even in relatively high-volume applications. There are two main advantages when using SIPs:
- Since the DDR SDRAM is integrated into the chip itself, it’s a bit quicker and easier to route the PCB, and you can use crappier PCB design software without having to bend over backward too much.
- These chips can dramatically reduce the size of your PCB, allowing you to squeeze Linux into smaller form factors.
SIPs look extremely attractive if you’re just building simple CPU break-out boards, since DDR routing will take up a large percentage of the design time.
But if you’re building real products that harness the capabilities of these processors — with high-resolution displays, image sensors, tons of I2C devices, sensitive analog circuitry, power/battery management, and application-specific design work — the relative time it takes to route a DDR memory bus starts to shrink to the point where it becomes negligible.
Also, as much as SIPs make things easier, most CPUs are not available in SIP packages and the ones that are usually ask a higher price than buying the CPU and RAM separately. Also, many SIP-enabled processors top out at 128-256 MB of RAM, which may not be enough for your application, while the regular ol’ processors reviewed here can address up to either 1 or 2 GB of external DDR3 memory.

Nuvoton NUC980
The Nuvoton NUC980 is a new 300 MHz ARM9-based SIP with 64 or 128 MB of SDRAM memory built-in. The entry-level chip in this family is $4.80 in quantities of 100, making it one of the cheapest SIPs available. Plus, Nuvoton does 90% discounts on the first five pieces you buy when purchased through TechDesign, so you can get a set of chips for your prototype for a couple of bucks.
This part sort of looks like something you’d find from one of the more mainstream application processor vendors: the full-sized version of this chip has two SDIO interfaces, dual ethernet MACs, dual camera sensor interfaces, two USB ports, four CAN buses, eight channels of 16-bit PWM (with motor-friendly complementary drive support), six 32-bit timers with all the capture/compare features you’d imagine, 12-bit ADC with 8 channels, 10 UARTs, 4 I2Cs, 2 SPIs, and 1 I2S — as well as a NAND flash and external bus interface.
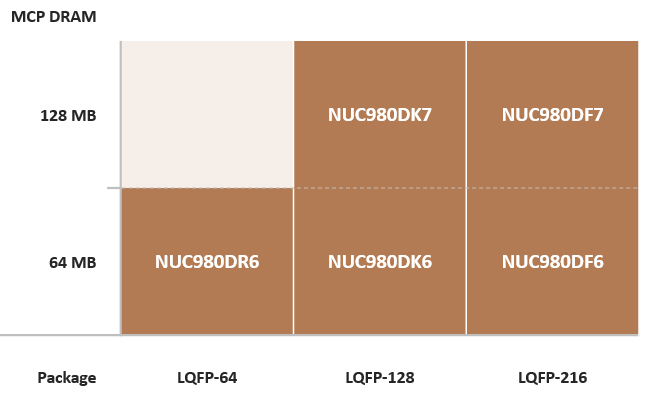
But, being Nuvoton, this chip has some (mostly good) weirdness up its sleeve. Unlike the other mainstream parts that were packaged in ~270 ball BGAs, the NUC980 comes in 216-pin, 128-pin, and even 64-pin QFP packages. I’ve never had issues hand-placing 0.8mm pitch BGAs, but there’s definitely a delight that comes from running Linux on something that looks like it could be a little Cortex-M microcontroller.
Another weird feature of this chip is that in addition to the 2 USB high-speed ports, there are 6 additional “host lite” ports that run at full speed (12 Mbps). Nuvoton says they’re designed to be used with cables shorter than 1m. My guess is that these are basically full-speed USB controllers that just use normal GPIO cells instead of fancy-schmancy analog-domain drivers with controlled output impedance, slew rate control, true differential inputs, and all that stuff.
Honestly, the only peripheral omission of note is the lack of a parallel RGB LCD controller. Nuvoton is clearly signaling that this part is designed for IoT gateway and industrial networked applications, not HMI. That’s unfortunate since a 300-MHz ARM9 is plenty capable of running basic GUIs. The biggest hurdle would be finding a place to stash a large GUI framework inside the limited SPI flash these devices usually boot from.
There’s also an issue with using these for IoT applications: the part offers no secure boot capabilities. That means people will be able to read out your system image straight from SPI flash and pump out clones of your device — or reflash it with alternative firmware if they have physical access to the SPI flash chip. You can still distribute digitally-signed firmware updates, which would allow you to verify a firmware image before reflashing it, but if physical device security is a concern, you’ll want to move along.
Hardware Design
For reference hardware, Nuvoton has three official (and low-cost) dev boards. The $60 NuMaker-Server-NUC980 is the most featureful; it breaks out both ethernet ports and showcases the chip as a sort of Ethernet-to-RS232 bridge. I purchased the $50 NuMaker-IIoT-NUC980, which had only one ethernet port but used SPI NAND flash instead of NOR flash. They have a newer $30 NuMaker-Tomato board that seems very similar to the IoT dev board. I noticed they posted schematics for a reference design labeled “NuMaker-Chili” which appears to showcase the diminutive 64-pin version of the NUC980, but I’m not sure if or when this board will ship.
Speaking of that 64-pin chip, I wanted to try out that version for myself, just for the sake of novelty (and to see how the low-pin-count limitations affected things). Nuvoton provides excellent hardware documentation for the NUC980 series, including schematics for their reference designs, as well as a NUC980 Series Hardware Design Guide that contains both guidelines and snippets to help you out.
Nuvoton has since uploaded design examples for their 64-pin NUC980, but this documentation didn’t exist when I was working on my break-out board for this review, so I had to make some discoveries on my own: because only a few of the boot selection pins were brought out, I realized I was stuck booting from SPI NOR Flash memory, which gets very expensive above 16 or 32 MB (also, be prepared for horridly slow write speeds).
Regarding booting: there are 10 boot configuration signals, labeled Power-On Setting in the datasheet. Luckily, these are internally pulled-up with sensible defaults, but I still wish most of these were determined automatically based on probing. I don’t mind having two pins to determine the boot source, but it should not be necessary to specify whether you’re using SPI NAND or NOR flash memory since you can detect this in software, and there’s no reason to have a bus width setting or speed setting specified — the boot ROM should just operate at the slowest speed, since the bootloader will hand things over to u-boot’s SPL very quickly, which can use a faster clock or wider bus to load stuff.
Other than the MPU and the SPI flash chip, you’ll need a 12 MHz crystal, a 12.1k USB bias resistor, a pull-up on reset, and probably a USB port (so you can reprogram the SPI flash in-circuit using the built-in USB bootloader on the NUC980). Sprinkle in some decoupling caps to keep things happy, and that’s all there is to it. The chip even uses an internal VDD/2 VREF source for the on-chip DDR, so there’s no external voltage divider necessary.
For power, you’ll need 1.2, 1.8, and 3.3 V supplies — I used a fixed-output 3.3V linear regulator, as well as a dual-channel fixed-output 1.2/1.8V regulator. According to the datasheet, the 1.2V core draws 132 mA, and the 1.8V memory supply tops out at 44 mA. The 3.3V supply draws about 85 mA.
Once you have everything wired up, you’ll realize only 35 pins are left for your I/O needs. Signals are multiplexed OK, but not great: SDHC0 is missing a few pins and SDHC1 pins are multiplexed with the Ethernet, so if you want to do a design with both WiFi and Ethernet, you’ll need to operate your SDIO-based wifi chip in legacy SPI mode.
The second USB High-Speed port isn’t available on the 64-pin package, so I wired up a USB port to one of the full-speed “Host Lite” interfaces mentioned previously. I should have actually read the Hardware Design Guide instead of just skimming through it since it clearly shows that you need external pull-down resistors on the data pins (along with series-termination resistors that I wasn’t too worried about) — this further confirms my suspicion that these Host Lite ports just use normal I/O cells. Anyway, this turned out to be the only bodge I needed to do on my board.
On the 64-pin package, even with the Ethernet and Camera sensor allocated, you’ll still get an I2C bus, an I2S interface, and an application UART (plus the UART0 used for debugging), which seems reasonable. One thing to note: there’s no RTC oscillator available on the 64-pin package, so I wouldn’t plan on doing time-keeping on this (unless I had an NTP connection).
If you jump to the 14x14mm 0.4mm-pitch 128-pin version of the chip, you’ll get 87 I/O, which includes a second ethernet port, a second camera port, and a second SDHC port. If you move up to the 216-pin LQFP, you’ll get 100 I/O — none of which nets you anything other than a few more UARTs/I2Cs/SPIs, at the expense of trying to figure out where to cram in a 24x24mm chip on your board.
Software
The NUC980 BSP seems to be built and documented for people who don’t know anything about embedded Linux development. The NUC980 Linux BSP User Manual assumes your main system is a Windows PC, and politely walks you through installing the “free” VMWare Player, creating a CentOS-based virtual machine, and configuring it with the missing packages necessary for cross-compilation.
Interestingly, the original version of NuWriter — the tool you’ll use to flash your image to your SPI flash chip using the USB bootloader of the chip — is a Windows application. They have a newer command-line utility that runs under Linux, but this should illustrate where these folks are coming from.
They have a custom version of Buildroot, but they also have an interesting BSP installer that will get you a prebuilt kernel, u-boot, and rootfs you can start using immediately if you’re just interested in writing applications. Nuvoton also includes small application examples for CAN, ALSA, SPI, I2C, UART, camera, and external memory bus, so if you’re new to embedded Linux, you won’t have to run all over the Internet as much, searching for spidev demo code, for example.

Instead of using the more-standard Device Tree system for peripheral configuration, by default Nuvoton has a funky menuconfig-based mechanism.
For seasoned Linux developers, things get a bit weird when you start pulling back the covers. Instead of using a Device Tree, they actually use old-school platform configuration data by default (though they provide a device tree file, and it’s relatively straightforward to configure Linux to just append the DTB blob to the kernel so you don’t have to rework all your bootloader stuff).
The platform configuration code is interesting because they’ve set it up so that much of it is actually configured using Kconfig; you can enable and disable peripherals, configure their options, and adjust their pinmux settings all interactively through menuconfig. To new developers, this is a much softer learning curve than rummaging through two or three layers of DTS include files to try to figure out a node setting to override.
The deal-breaker for a lot of people is that the NUC980 has no mainline support — and no apparent plans to try to upstream their work. Instead, Nuvoton distributes a 4.4-series kernel with patches to support the NUC980. The Civil Infrastructure Platform (CIP) project plans to maintain this version of the kernel for a minimum of 10 years — until at least 2026. It looks like Nuvoton occasionally pulls patches in from upstream, but if there’s something broken (or a vulnerability), you might have to ask Nuvoton to pull it in (or do it yourself).
I had issues getting their Buildroot environment working, simply because it was so old — they’re using version 2016.11.1. There were a few host build tools on my Mint 19 VM that were “too new” and had minor incompatibilities, but after posting issues on GitHub, the Nuvoton engineer who maintains the repo fixed things.
Here’s a big problem Nuvoton needs to fix: by default, Nuvoton’s BSP is set up to boot from an SPI flash chip with a simple initrd filesystem appended to the uImage that’s loaded into RAM. This is a sensible configuration for a production application, but it’s definitely a premature optimization that makes development challenging — any modifications you make to files will be wiped away on reboot (there’s nothing more exciting than watching sshd generate a new keypair on a 300 MHz ARM9 every time you reboot your board). Furthermore, I discovered that if the rootfs started getting “too big” Linux would fail to boot altogether.
Instead, the default configuration should store the rootfs on a proper flash filesystem (like YAFFS2), mounted read-write. Nuvoton doesn’t provide a separate Buildroot defconfig for this, and for beginners (heck, even for me), it’s challenging to switch the system over to this boot strategy, since it involves changing literally everything — the rootfs image that Buildroot generates, the USB flash tool’s configuration file, U-Boot’s bootcmd, and Linux’s Kconfig.
Even with the initrd system, I had to make a minor change to U-boot’s Kconfig, since by default, the NUC980 uses the QSPI peripheral in quad mode, but my 64-pin chip didn’t have the two additional pins broken out, so I had to operate it in normal SPI mode. They now have a “chilli” defconfig that handles this.
In terms of support, Nuvoton’s forum looks promising, but the first time you post, you’ll get a notice that your message will need administrative approval. That seems reasonable for a new user, but you’ll notice that all subsequent posts also require approval, too. This makes the forum unusable — instead of serving as a resource for users to help each other out, it’s more or less an area for product managers to shill about new product announcements.
Instead, go straight to the source — when I had problems, I just filed issues on the GitHub repos for the respective tools I used (Linux, U-Boot, BuildRoot, NUC980 Flasher). Nuvoton engineer Yi-An Chen and I kind of had a thing for a while where I’d post an issue, go to bed, and when I’d wake up, he had fixed it and pushed his changes back into master. Finally, the time difference between the U.S. and China comes in handy!

Allwinner F1C100s / F1C200s
The F1C100s and F1C200s are identical ARM9 SIP processors with either 32 MB (F1C100s) or 64 MB (F1C200s) SDRAM built-in. They nominally run at 400 MHz but will run reliably at 600 MHz or more.
These parts are built for low-cost AV playback and feature a 24-bit LCD interface (which can also be multiplexed to form an 18-bit LCD / 8-bit camera interface), built-in audio codec, and analog composite video in/out. There’s an H.264 video decoder that you’ll need to be able to use this chip for video playback. Just like with the A33, the F1C100s has some amazing multimedia hardware that’s bogged down by software issues with Allwinner — the company isn’t set up for typical Yocto/Buildroot-based open-source development. The parallel LCD interface and audio codec are the only two of these peripherals that have mainline Linux support; everything else only currently works with the proprietary Melis operating system Allwinner distributes, possibly an ancient 3.4-series kernel they have kicking around, along with their proprietary CedarX software (though there is an open-source effort that’s making good progress, and will likely end up supporting the F1C100s and F1C200s).
Other than that, these parts are pretty bare-bones in terms of peripherals: there’s a single SDIO interface, a single USB port, no Ethernet, really no programmable timer resources (other than two simple PWM outputs), no RTC, and just a smattering of I2C/UART/SPI ports. Like the NUC980, this part has no secure boot / secure key storage capabilities — but it also doesn’t have any sort of crypto accelerator, either.
The main reason you’d bother with the hassle of these parts is the size and price: these chips are packaged in a 10x10mm 88-pin QFN and hover in the $1.70 range for the F1C100s and $2.30 for the F1C200s. Like the A33, the F1C100s doesn’t have good availability outside of China; Taobao will have better pricing, but AliExpress provides an English-language front-end and easy U.S. shipping.
The most popular piece of hardware I’ve seen that uses these is the Bittboy v3 Retro Gaming handheld (YouTube teardown video).
Hardware Design
There may or may not be official dev boards from Allwinner, but most people use the $7.90 Lichee Pi Nano as a reference design. This is set up to boot from SPI NOR flash and directly attach to a TFT via the standard 40-pin FPC pinouts used by low-cost parallel RGB LCDs.
Of all the parts reviewed here, these were some of the simplest to design hardware around. The 0.4mm-pitch QFN package provided good density while remaining easy to solder. You’ll end up with 45 usable I/O pins (plus the dedicated audio codec).
The on-chip DDR memory needs an external VDD/2 VREF divider, and if you want good analog performance, you should probably power the 3V analog supply with something other than the 2.5V noisy memory voltage as I did, but otherwise, there’s nothing more needed than your SPI flash chip, a 24 MHz crystal, a reset pull-up circuit, and your voltage regulators. There are no boot configuration pins or OTP fuses to program; on start-up, the processor attempts to boot from SPI NAND or NOR flash first, followed by the SDIO interface, and if neither of those work, it goes into USB bootloader mode. If you want to force the board to enter USB bootloader mode, just short the MOSI output from the SPI Flash chip to GND — I wired up a pushbutton switch to do just this.
The chip needs a 3.3V, 2.5V and 1.1V supply. I used linear regulators to simplify the BOM, and ended up using a dual-output regulator for the 3.3V and 2.5V rails. 15 BOM lines total (including the MicroSD card breakout).
Software
Software on the F1C100s, like all Allwinner parts, is a bit of a mess. I ended up just grabbing a copy of buildroot and hacking away at it until I got things set up with a JFFS2-based rootfs, this kernel and this u-boot. I don’t want this review to turn into a tutorial; there are many unofficial sources of information on the F1C100s on the internet, including the Lichee Pi Nano guide. Also of note, George Hilliard has done some work with these chips and has created a ready-to-roll Buildroot environment — I haven’t tried it out, but I’m sure it would be easier to use than hacking at one from scratch.
Once you do get everything set up, you’ll end up with a bog-standard mainline Linux kernel with typical Device Tree support. I set up my Buildroot tree to generate a YAFFS2 filesystem targeting an SPI NOR flash chip.
These parts have a built-in USB bootloader, called FEL, so you can reflash your SPI flash chip with the new firmware. Once again, we have to turn to the open-source community for tooling to be able to use this: the sunxi-tools package provides the sunxi-fel command-line utility for flashing images to the board. I like this flash tool much better than some of the other ones in this review — since the chip waits around once flashing is complete to accept additional commands, you can repeatedly call this utility from a simple shell script with all the files you want; there’s no need to combine the different parts of your flash image into a monolithic file first.
While the F1C100s / F1C200s can boot from SPI NAND or NOR flash, sunxi-fel only has ID support for SPI NOR flash. A bigger gotcha is that the flash-programming tool only supports 3-byte addressing, so it can only program the first 16MB of an SPI flash chip. This really limits the sorts of applications you can do with this chip — with the default memory layout, you’re limited to a 10 MB rootfs partition, which isn’t enough to install Qt or any other large application framework. I hacked at the tool a bit to support 4-byte address mode, but I’m still having issues getting all the pieces together to boot, so it’s not entirely seamless.

Microchip SAM9X60 SIP
The SAM9X60 is a new ARM9-based SoC released at the end of 2019. Its name pays homage to the classic AT91SAM9260. Atmel (now part of Microchip) has been making ARM microprocessors since 2006 when they released that part. They have a large portfolio of them, with unusual taxonomies that I wouldn’t spend too much time trying to wrap my head around. They classify the SAM9N, SAM9G, and SAM9X as different families — with their only distinguishing characteristic is that SAM9N parts only have 1 SDIO interface compared to the two that the other parts have, and the SAM9X has CAN while the others don’t. Within each of these “families,” the parts vary by operating frequency, peripheral selection, and even package.((One family, however, stands out as being considerably different from all the others. The SAM9XE is basically a 180 MHz ARM9 microcontroller with embedded flash.)) Don’t bother trying to make sense of it. And, really, don’t bother looking at anything other than the SAM9X60 when starting new projects.
While it carries a legacy name, this part is obviously intended to be a “reset” for Microchip. When introduced last year, it simultaneously became the cheapest and best SAM9 available — 600-MHz core clock, twice as much cache, tons more communication interfaces, twice-as-fast 1 MSPS ADC, and better timers. And it’s the first SAM-series application processor I’ve seen that carries a Microchip badge on the package.
All told, the SAM9X60 has 13 UARTs, 6 SPI, 13 I2C, plus I2s, parallel camera and LCD interfaces. It also features three proper high-speed USB ports (the only chip in this round-up that had that feature). Unlike the F1C100s and NUC980, this part has Secure Boot capability, complete with secure OTP key storage, tamper pins, and a true random number generator (TRNG). Like the NUC980, it also has a crypto accelerator. It does not have a trusted execution environment, though, which only exists in Cortex-A offerings.

This part doesn’t have true embedded audio codec like the F1C100s does, but it has a Class D controller, which looks like it’s essentially just a PWM-type peripheral, with either single-ended or differential outputs. I suppose it’s kind of a neat feature, but the amount of extraneous circuitry required will add 7 BOM lines to your project — far more than just using a single-chip Class-D amplifier.
This processor comes as a stand-alone MPU (which rings in less than $5), but the more interesting option integrates SDRAM into the package. This SIP option is available with SDR SDRAM (available in an 8 MB version), or DDR2 SDRAM (available in 64 and 128 MB versions). Unless you’re doing bare-metal development, stick with the 64MB version (which is $8), but mount the 128MB version ($9.50) to your prototype to develop on — both of these are housed in a 14x14mm 0.8mm-pitch BGA that’s been 20% depopulated down to 233 pins.
It’s important to note that people design around SIPs to reduce design complexity, not cost. While you’d think that integrating the DRAM into the package would be cheaper than having two separate ICs on your board, you always pay a premium for the difficult-to-manufacture SIP version of chips: pairing a bare SAM9X60 with a $1.60 stand-alone 64MB DDR2 chip is $6.60 — much less than the $8 SIP with the same capacity.Also, the integrated- and non-integrated-DRAM versions come with completely different ball-outs, so they’re not drop-in compatible.
If you’d like to try out the SAM9X60 before you design a board around it, Microchip sells the $260 SAM9X60-EK. It’s your typical old-school embedded dev board — complete with lots of proprietary connectors and other oddities. It’s got a built-in J-Link debugger, which shows that Microchip sees this as a viable product for bare-metal development, too. This is a pretty common trend in the industry that I’d love to see changed. I would prefer a simpler dev board that just breaks out all the signals to 0.1″ headers — maybe save for an RMII-connected Ethernet PHY and the MMC buses.
My issue is that none of these signals are particularly high-speed so there’s no reason to run them over proprietary connectors. Sure, it’s a hassle to breadboard something like a 24-bit RGB LCD bus, but it’s way better than having to design custom adapter boards to convert the 0.5mm-pitch FPC connection to whatever your actual display uses.
These classic dev board designs are aptly named “evaluation kits” instead of “development platforms.” They end up serving more as a demonstration that lets you prototype an idea for a product — but when it comes time to actually design the hardware, you have to make so many component swaps that your custom board is no longer compatible with the DTS / drivers you used on the evaluation kit. I’m really not a fan of these (that’s one of the main reasons I designed a bunch of breakout boards for all these chips).
Hardware Design
Microchip selectively-depopulated the chip in such a way that you can escape almost all I/O signals on the top layer. There are also large voids in the interior area which gives ample room for capacitor placement without worrying about bumping into vias. I had a student begging me to let him lay out a BGA-based embedded Linux board, and this processor provided a gentle introduction.
Powering the SAM9X60 is a similar affair to the NUC980 or F1C100s. It requires 3.3V, 1.8V and 1.2V supplies — we used a 3.3V and dual-channel 1.8/1.2V LDO. In terms of overall design complexity, it’s only subtly more challenging than the other two ARM9s. It requires a precision 5.62k bias resistor for USB, plus a 20k precision resistor for DDR, in addition to a DDR VREF divider. There’s a 2.5V internal regulator that must be bypassed.
But this is the complexity you’d expect from a mainstream vendor who wants customers to slide through EMC testing without bothering their FAEs too much.
The 233-ball package provides 112 usable I/O pins — more than any other ARM9 reviewed.
Unfortunately, most of these additional I/O pins seem to focus on reconfigurable SPI/UART/I2C communication interfaces (FLEXCOMs) and a parallel NAND flash interface (which, from the teardowns I’ve seen, is quickly falling out of style among engineers). How many UARTs does a person really need? I’m trying to think of the last time I needed more than two.
The victim of this haphazard pin-muxing is the LCD and CSI interfaces, which have overlapping pins. And Microchip didn’t even do it in a crafty way like the F1C100s where you could still run an LCD (albeit in 16-bit mode) with an 8-bit camera sensor attached.
Software Design
This is a new part that hasn’t made its way into the main Buildroot branch yet, but I grabbed the defconfig and board folder from this Buildroot-AT91 branch. They’re using the linux4sam 4.4 kernel, but there’s also mainline Linux support for the processor, too.
The Buildroot/U-Boot defconfig was already set up to boot from a MicroSD card, which makes it much easier to get going quickly on this part; you don’t have to fiddle with configuring USB flasher software as I did for the SPI-equipped NUC980 and F1C100s board, and your rootfs can be as big as you’d like. Already, that makes this chip much easier to get going — you’ll have no issues throwing on SSH, GDB, Python, Qt, and any other tools or frameworks you’re interested in trying out.
Just remember that this is still just an ARM9 processor; it takes one or two minutes to install a single package from pip, and you might as well fix yourself a drink while you wait for SSH to generate a keypair. I tested this super simple Flask app (which is really just using Flask as a web server) and page-load times seemed completely reasonable; it takes a couple seconds to load large assets, but I don’t think you’d have any issue coaxing this processor into light-duty web server tasks for basic smart home provisioning or configuration.

The DTS files for both this part and the SAMA5D27 below were a bit weird. They don’t use phandles at all for their peripherals; everything is re-declared in the board-specific DTS file, which makes them extremely verbose to navigate. Since they have labels in their base DTS file, it’s a simple fix to rearrange things in the board file to reference those labels — I’ve never seen a vendor do things this way, though.
As is typical, they require that you look up the actual peripheral alternate-function mode index — if you know a pin has, say, I2C2_SDA capability, you can’t just say you want to use it with “I2C2.” This part has a ton of pins and not a lot of different kinds of peripherals, so I’d imagine most people would just leave everything to the defaults for most basic applications.
The EVK DTS has pre-configurated pinmux schemes for RGB565, RGB666, and RGB888 parallel LCD interfaces, so you can easily switch over to whichever you’re using. The default timings were reasonable; I didn’t have to do any configuration to interface the chip with a standard 5″ 800×480 TFT. I threw Qt 5 plus all the demos on an SD card, plugged in a USB mouse to the third USB port, and I was off to the races. Qt Quick / QML is perfectly useable on this platform, though you’re going to run into performance issues if you start plotting a lot of signals. I also noticed the virtual keyboard tends to stutter when changing layouts.
Documentation is fairly mixed. AN2772 covers the basics of embedded Linux development and how it relates to the Microchip ecosystem (a document that not every vendor has, unfortunately). But then there are huge gaping holes: I couldn’t really track down much official documentation on SAM-BA 3.x, the new command-line version of their USB boot monitor application used to program fuses and load images if you’re using on-board flash memory. Everything on Microchip’s web site is for the old 2.x series version of SAM-BA, which was a graphical user interface. Most of the useful documentation is on the Linux4SAM wiki.

Microchip SAMA5D27 SIP
With their acquisition of Atmel, Microchip inherited a line of application processors built around the Cortex-A5 — an interesting oddity in the field of slower ARM9 cores and faster Cortex-A7s in this roundup. The Cortex-A5 is basically a Cortex-A7 with only a single-width instruction decode and optional NEON (which our particular SAMA5 has).

There are three family members in the SAMA5 klan, and, just like the SAM9, they all have bizarre product differentiation.
The D2 part features 500 MHz operation with NEON and TrustZone, a DDR3 memory controller, ethernet, two MMC interfaces, 3 USB, CAN, plus LCD and camera interfaces. Moving up to the D3, we bump up to 536 MHz, lose the NEON and TrustZone extensions, lose the DDR3 support, but gain a gigabit MAC. Absolutely bizarre. Moving up to the D4, and we get our NEON and TrustZone back, still no DDR3, but now we’re at 600 MHz and we have a 720p30 h.264 decoder.
I can’t make fun of this too much, since lots of companies tailor-make application processors for very specific duties; they’ve decided the D2 is for secure IoT applications, the D3 is for industrial work, and the D4 is for portable multimedia applications.
Zooming into the D2 family, these seem to only vary by CAN controller presence, die shield (for some serious security!), and I/O count (which I suppose also affects peripheral counts). The D27 is nearly the top-of-the-line model, featuring 128 I/O, a 32-bit-wide DDR memory bus (twice the width of every other part reviewed), a parallel RGB LCD controller, parallel camera interface, Ethernet MAC, CAN, cap-touch, 10 UARTs, 7 SPIs, 7 I2Cs, two MMC ports, 12 ADC inputs, and 10 timer/PWM pins.
Like the SAM9X60, these parts feature good secure-boot features, as well as standard crypto acceleration capabilities. Microchip has an excellent app note that walks you through everything required to get secure boot going. Going a step further, this is the first processor in our review that has TrustZone, with mature support in OP-TEE.
These D2 chips are available in several different package sizes: a tiny 8x8mm 256-ball 0.4mm (!) pitch BGA with lots of selective depopulations, an 11×11 189-ball 0.75mm-pitch full-rank BGA, and a 14x14mm 289-ball 0.8mm-pitch BGA, also full-rank.
The more interesting feature of this line is that many of these have a SIP package available. The SIP versions use the same packaging but different ball-outs. They’re available in the 189- and 289-ball packages, along with a larger 361-ball package that takes advantage of the 32-bit-wide memory bus (the only SIP I know that does this). I selected the SAMA5D27-D1G to review — these integrate 128 MB of DDR2 memory into the 289-ball package.
For evaluation, Microchip has the $200 ATSAMA5D27-SOM1-EK, which actually uses the SOM — not SIP — version of this chip. It’s a pretty typical dev board that’s similar to the SAM9X60-EK, so I won’t rehash my opinions on this style of evaluation kit.

Hardware Design
As we’ve seen before, the SAMA5 uses a triple-supply 3.3V/1.8V/1.2V configuration for I/O, memory, and core. There’s an additional 2.5V supply you must provide to program the fuses if necessary, but Microchip recommends leaving the supply unpowered during normal operation.
The SIP versions of these parts use Revision C silicon (MRL C, according to Microchip documentation). If you’re interested in the non-SIP version of this part, make sure to opt for the C revision. Revision A of the part is much worse than B or C — with literally twice as much power consumption. Revision B fixed the power consumption figures, but can’t boot from the SDMMC interface (!!) because of a card-detect sampling bug. Revision C fixes that bug and provides default booting from SDMMC0 and SDMMC1 without needing to do any SAM-BA configuration.
Escaping signals from this BGA is much more challenging than most other chips in this review, simply because it has a brain-dead pin-out. The IC only has 249 signals, but instead of selectively-depopulating a 289-ball package like the SAM9X60 does, Microchip leaves the package full-rank and simply marks 40 of these pins as “NC” — forcing you to carefully route around these signals. Rather than putting these NC pins toward the middle of the package, they’re bumped up in the corner, which is awful to work around.
The power supply pins are also randomly distributed throughout the package, with signal pins going all the way to the center of the package — 8 rows in. This makes 4-layer fanout trickier since there are no internal signal layers to route on. In the end, I couldn’t implement Microchip’s recommended decoupling capacitor layout since I simply didn’t have room on the bottom layer. This wasn’t an issue at all with the other BGAs in the round-up, which all had centralized power supply pins, or at least a central ground island and/or plenty of voids in the middle area of the chip.
However, once you do get everything fanned out, you’ll be rewarded with 128 usable I/O pins —second only to the 355-ball RK3308. And that doesn’t include the dedicated audio PLL clock output or the two dedicated USB transceivers (ignore the third port in my design — it’s an HSIC-only USB peripheral). There are no obvious multiplexing gotchas that the Allwinner or SAM9X60 parts have, and the sheer number of comms interfaces gives you plenty of routing options if you have a large board with a lot of peripherals on it.
There’s only a single weird 5.62k bias resistor needed, in addition to the DDR VDD/2 reference divider. They ball out the ODT signal, which should be connected to GND for DDR2-based SIPs like the one I used.
And if you’ve ever wondered about the importance of decoupling caps: I got a little too ahead of myself when these boards came off the hot plate — I plugged them in and started running benchmarking tests before realizing I completely forgot to solder the bottom side of the board full of all the decoupling capacitors. The board ran just fine!((Yes, yes, obviously, if you actually wanted to start depopulating bypass capacitors in a production setting, you’d want to carefully evaluate the analog performance of the part — ADC inputs, crystal oscillator phase jitter, and EMC would be of top concern to me.))
Software
Current-generation MRL-C devices, like the SIPs I used, will automatically boot from MMC0 without needing to use the SAM-BA monitor software to burn any boot fuses or perform any configuration at all. But, as is common, it won’t even attempt to boot off the card if the card-detect signal (PA13) isn’t grounded.
When U-boot finally did start running, my serial console was gibberish and appeared to be outputting text at half the baud I had expected. After adjusting the baud, I realized U-boot was compiled assuming a 24 MHz crystal (even though the standard SAMA5D2 Xplained board uses a 12 MHz). This blog post explained that Microchip switched the config to a 24 MHz crystal when making their SOM for this chip.
The evaluation kits all use eMMC memory instead of MicroSD cards, so I had to switch the bus widths over to 8 bits. The next problem I had is that the write-protect GPIO signal on the SDMMC peripheral driver doesn’t respect your device tree settings and is always enabled. If this pin isn’t shorted to GND, Linux will think the chip has write protection enabled, causing it to throw a -30 error code (read-only filesystem error) on boot-up. I ended up adding a wp-inverted declaration in the device tree as a hack, but if I ever want to use that GPIO pin for something else, I’ll have to do some more investigation.
As for documentation, it’s hit or miss. On their product page, they have some cute app notes that curate what I would consider “standard Linux canon” in a concise place to help you use peripherals from userspace in C code (via spidev, i2cdev, sysfs, etc), which should help beginners who are feeling a bit overwhelmed.

Allwinner V3s
The Allwinner V3s is the last SIP we’ll look at in this review. It pairs a fast 1 GHz Cortex-A7 with 64 MB of DDR2 SDRAM. Most interestingly, it has a build-in audio codec (with microphone preamp), and an Ethernet MAC with a built-in PHY — so you can wire up an ethernet mag jack directly to the processor.
Other than that, it has a basic peripheral set: two MMC interfaces, a parallel RGB LCD interface that’s multiplexed with a parallel camera sensor interface, a single USB port, two UARTs, one SPI, and two I2C interfaces. It comes in a 128-pin 0.4mm-pitch QFP.
Hardware Design
Just like with the F1C100s, there’s not a lot of official documentation for the V3s. There’s a popular, low-cost, open-source dev board, the Lichee Pi Zero, which serves as a good reference design and a decent evaluation board.
The QFP package makes PCB design straightforward; just like with the NUC980 and F1C100s, I had no problems doing a single-sided design. On the other hand, I found the package — with its large size and 0.4mm pitch — relatively challenging to solder (I had many shorts that had to be cleaned up). The large thermal pad in the center serves as the only GND connection and makes the chip impossible to pencil-solder without resorting to a comically-large via to poke your soldering iron into.
Again, there are three voltage domains — 3.3V for I/O, 1.8V for memory, and 1.2V for the core voltage. External component requirements are similar to the F1C200s — an external VREF divider, precision bias resistor, and a main crystal — but the V3s adds an RTC crystal.
With dedicated pins for the PHY, audio CODEC, and MIPI camera interface, there are only 51 I/O pins on the V3s, with MMC0 pins multiplexed with a JTAG, and two UARTs overlapped with two I2C peripherals, and the camera and LCD parallel interface on top of each other as well.
To give you an idea about the sort of system you might build with this chip, consider a product that uses UART0 as the console, an SPI Flash boot chip, MMC0 for external MicroSD storage, MMC1 and a UART for a WiFi/BT combo module, and I2C for a few sensors. That leaves an open LCD or camera interface, a single I2C port or UART, and… that’s it.
In addition to the massive number of shorts I had when soldering the V3s, the biggest hardware issue I had was with the Ethernet PHY — no one on my network could hear packets I was sending out. I realized the transmitter was particularly sensitive and needed a 10 uH (!!!) inductor on the center-tap of the mags to work properly. This is clearly documented in the Lichee Pi Base schematics, but I thought it was a misprint and used a ferrite bead instead. Lesson learned!
Software Design
With official Buildroot support for the V3s-based Lichee Pi Zero, software on the V3s is a breeze to get going, but due to holes in mainline Linux support, some of the peripherals are still unavailable. Be sure to mock-up your system and test peripherals early on, since much of the BSP has been quickly ported from other Allwinner chips and only lightly tested. I had a group in my Advanced Embedded Systems class last year who ended up with a nonfunctional project after discovering late into the process that the driver for the audio CODEC couldn’t simultaneously play and record audio.
I’ve played with this chip rather extensively and can confirm the parallel camera interface, parallel RGB LCD interface, audio codec, and comms interfaces are relatively straightforward to get working. Just like the F1C100s, the V3s doesn’t have good low-power support in the kernel yet.

NXP i.MX 6UL/6ULL/6ULZ
The i.MX 6 is a broad family of application processors that Freescale introduced in 2011 before the NXP acquisition. At the high end, there’s the $60 i.MX 6QuadMax with four Cortex-A9 cores, 3D graphics acceleration, and support for MIPI, HDMI, or LVDS. At the low end, there’s the $2.68 i.MX 6ULZ with…. well, basically none of that.
For full disclosure, NXP’s latest line of processors is actually the i.MX 8, but these parts are really quite a bit of a technology bump above the other parts in this review and didn’t seem relevant for inclusion. They’re either $45 each for the massive 800+ pin versions that come in 0.65mm-pitch packages, or they come in tiny 0.5mm-pitch BGAs that are annoying to hand-assemble (and, even with the selectively depopulated pin areas, look challenging to fan-out on a standard-spec 4-layer board). They also have almost a dozen supply rails that have to be sequenced properly. I don’t have anything against using them if you’re working in a well-funded prototyping environment, but this article is focused on entry-level, low-cost Linux-capable chips.
We may yet see a 0.8mm-pitch low-end single- or dual-core i.MX 8, as Freescale often introduces higher-end parts first. Indeed, the entry-level 528 MHz i.MX 6UltraLite (UL) was introduced years after the 6SoloLite and SoloX (Freescale’s existing entry-level parts) and represented the first inexpensive Cortex-A7 available.
The UL has built-in voltage regulators and power sequencing, making it much easier to power than other i.MX 6 designs. Interestingly, this part can address up to 2 GB of RAM (the A33 was the only other part in this review with that capability). Otherwise, it has standard fare: a parallel display interface, parallel camera interface, two MMC ports, two USB ports, two fast Ethernet ports, three I2S, two SPDIF, plus tons of UART, SPI, and I2C controllers. These specs aren’t wildly different than the 6SoloLite / SoloX parts, yet the UL is half the price.
This turns out to be a running theme: there has been a mad dash toward driving down the cost of these parts (perhaps competition from TI or Microchip has been stiff?), but interestingly, instead of just marking down the prices, NXP has introduced new versions of the chip that are essentially identical in features — but with a faster clock and a cheaper price tag.
The 6ULL (UltraLiteLite?) was introduced a couple of years after the UL and features essentially the same specs, in the same package, with a faster 900-MHz clock rate, for the same price as the UL. This part has three SKUs: the Y0, which has no security, LCD/CSI, or CAN (and only one Ethernet port), the Y1, which adds basic security and CAN, and the Y2, which adds LCD/CSI, a second CAN, and a second Ethernet. The latest part — the 6ULZ — is basically the same as the Y1 version of the 6ULL, but with an insanely-cheap $2.68 price tag.
I think the most prominent consumer product that uses the i.MX 6UL is the Nest Thermostat E, though, like TI, these parts end up in lots and lots of low-volume industrial products that aren’t widely seen in the consumer space. Freescale offers the $149 MCIMX6ULL-EVK to evaluate the processor before you pull the trigger on your own design. This is an interesting design that splits the processor out to its own SODIMM-form-factor compute module and a separate carrier board, allowing you drop the SOM into your own design. The only major third-party dev board I found is the $39 Seeed Studio NPi. There’s also a zillion PCB SoM versions of i.MX 6 available from vendors of various reputability; these are all horribly expensive for what you’re getting, so I can’t recommend this route.
Hardware Design
I tried out both the newer 900 MHz i.MX 6ULL, along with the older 528-MHz 6UL that I had kicking around, and I can verify these are completely drop-in compatible with each other (and with the stripped-down 6ULZ) in terms of both software and hardware. I’ll refer to all these parts collectively as “UL” from here on out.
These parts come in a 289-ball 0.8mm-pitch 14x14mm package — smaller than the Atmel SAMA5D27, the Texas Instruments AM335x and the ST STM32MP1. Consequently, there are only 106 usable I/O on this part, and just like with most parts reviewed here, there’s a lot of pin-muxing going on.((NXP names the pin with the default alternate function, not a basic GPIO port name, so be prepared for odd-looking pin-muxing names, like I2C1_SCL__UART4_TX_DATA.))
The i.MX 6 series is one of the easiest parts to design when compared to similar-scale parts from other vendors. This is mostly due to its unique internal voltage regulator scheme: A 1.375-nominal VDD_SOC power is brought in and internally regulated to a 0.9 – 1.3V core voltage, depending on CPU speed. There are additional internal regulators and power switches for 1.1V PLLs, 2.5V analog-domain circuitry, 3.3V USB transceivers, and coin cell battery-backed memory. By using DDR3L memory, I ended up using nothing but two regulators — a 1.35V and 3.3V one — to power the entire system. For power sequencing, the i.MX 6 simply requires the 3.3V rail to come up before the 1.35V one.
One hit against the i.MX 6 is the DRAM ball-out: The data bus seems completely discombobulated. I ended up swapping the two data lanes and also swapping almost all the pins in each lane, which I didn’t have to do with any other part reviewed here.
For booting, there are 24 GPIO bootstrap pins that can be pulled (or tied if otherwise unused) high or low to specify all sorts of boot options. Once you’ve set this up and verified it, you can make these boot configurations permanent with a write to the boot configuration OTP memory (that way, you don’t have to route all those boot pins on production boards).
Best of all, if you’re trying to get going quickly and don’t want to throw a zillion pull-up/pull-down resistors into your design, there’s an escape hatch: if none of the boot fuses have been programmed and the GPIO pins aren’t set either, the processor will attempt to boot off the first MMC device, which you could, say, attach to a MicroSD card. Beautiful!
Software Workflow
Linux and U-Boot both have had mainline support for this architecture for years. NXP officially supports Yocto, but Buildroot also has support. If you want to use the SD/MMC Manufacture Mode option to boot directly off a MicroSD card without fiddling with boot pins or blowing OTP fuses, you’ll have to modify U-Boot. I submitted a patch years ago to the official U-Boot mailing list as well as a pull request to u-boot-fslc, but it’s been ignored. The only other necessary change is to switch over the SDMMC device in the U-Boot mx6ullevk.h port.

Compared to others in this round-up, DTS files for the i.MX 6 are OK. They reference a giant header file with every possible pinmux setting predefined, so you can autocomplete your way through the list to establish the mux setting, but you’ll still need to calculate a magical binary number to configure the pin itself (pull-up, pull-down, drive strength, etc). Luckily, these can usually be copied from elsewhere (or if you’re moving a peripheral from one set of pins to another, there’s probably no need to change). I still find this way better than DTS files that require you look up the alternate-function number in the datasheet.
NXP provides a pinmuxing tool that can automatically generate DTS pinmux code which makes this far less burdensome, but for most projects, I’d imagine you’d be using mostly defaults anyway — with only light modifications to secure an extra UART, I2C, or SPI peripheral, for example.
Windows 10 IoT Core
The i.MX 6 is the only part I reviewed that has first-party support for Windows 10 IoT Core, and although this is an article about embedded Linux, Windows 10 IoT core competes directly with it and deserves mention. I downloaded the source projects which are divided into a Firmware package that builds an EFI-compliant image with U-Boot, and then the actual operating system package. I made the same trivial modifications to U-Boot to ensure it correctly boots from the first MMC device, recompiled, copied the new firmware to the board, and Windows 10 IoT core booted up immediately.
OK, well, not immediately. In fact, it took 20 or 30 minutes to do the first boot and setup. I’m not sure the single-core 900 MHz i.MX 6ULL is the part I would want to use for Windows 10 IoT-based systems; it’s just really, really slow. Once everything was set up, it took more than a minute and a half from when I hit the “Start Debugging” button in Visual Studio to when I landed on my InitializeComponent() breakpoint in my trivial UWP project. It looks to be somewhat RAM-starved, so I’d like to re-evaluate on a board that has 2 GB of RAM (the board I was testing just had a 512-MB part mounted).

Allwinner A33
Our third and final Allwinner chip in the round-up is an older quad-core Cortex-A7 design. I picked this part because it has a sensible set of peripherals for most embedded development, as well as good support in Mainline Linux. I also had a pack of 10 of them laying around that I had purchased years ago and never actually tried out.
This part, like all the other A-series parts, was designed for use in Android tablets — so you’ll find Arm Mali-based 3D acceleration, hardware-accelerated video decoding, plus LVDS, MIPI and parallel RGB LCD support, a built-in audio codec, a parallel camera sensor interface, two USB HS ports, and three MMC peripherals — an unusually generous complement.
There’s an open-source effort to get hardware video decoding working on these parts. They currently have MPEG2 and H264 decoding working. While I haven’t had a chance to test it on the A33, this is an exciting development — it makes this the only part in this round-up that has a functional hardware video decoder.
Additionally, you’ll find a smattering of lower-speed peripherals: two basic PWM channels, six UARTs, two I2S interfaces, two SPI controllers, four I2C controllers, and a single ADC input. The biggest omission is the Ethernet MAC.
This and the i.MX 6 are the only two parts in this round-up that can address a full 2 GB of memory (via two separate banks). I had some crazy-expensive dual-die 2 GB dual-rank DDR memory chips laying around that I used for this. You can buy official-looking A33 dev boards from Taobao, but I picked up a couple Olimex A33-OLinuXino boards to play with. These are much better than some of the other dev boards I’ve mentioned, but I still wish the camera CSI / MIPI signals weren’t stuck on an FFC connector.
Hardware Design
The A33 has four different voltage rails it needs, which starts to move the part up into PMIC territory. The PMIC of choice for the A33 is the AXP223. This is a great PMIC if you’re building a portable battery-powered device, but it’s far too complicated for basic always-on applications. It has 5 DC/DC converters, 10 LDO outputs, plus a lithium-ion battery charger and power-path switching capability.
After studying the documentation carefully, I tried to design around it in a way that would allow me to bypass the DC/DC-converter battery charger to save board space and part cost. When I got the board back, I spent a few hours trying to coax the chip to come alive, but couldn’t get it working in the time I had set aside.
Anticipating this, I had designed and sent off a discrete regulator version of the board as well, and that board booted flawlessly. To keep things simple on that discrete version, I used the same power trick with the A33 as I did on the i.MX 6, AM3358, and STM32MP1: I ran both the core and memory off a single 1.35V supply. There was a stray VCC_DLL pin that needed to be supplied with 2.5V, so I added a dedicated 2.5V LDO. The chip runs pretty hot when maxing out the CPU, and I don’t think running VDD_CPU and VDD_SYS (which should be 1.1V) at 1.35V is helping.
The audio codec requires extra bypassing with 10 uF capacitors on several bias pins which adds a bit of extra work, but not even the USB HS transceivers need an external bias resistor, so other than the PMIC woes, the hardware design went together smoothly.
Fan-out on the A33 is beautiful: power pins are in the middle, signal pins are in the 4 rows around the outside, and the DDR bus pinout is organized nicely. There is a column-long ball depopulation in the middle that gives you extra room to place capacitors without running into vias. There are no boot pins (the A33 simply tries each device sequentially, starting with MMC0), and there are no extraneous control / enable signals other than a reset and NMI line.

Software
The A33 OLinuXino defconfig in Buildroot, U-Boot, and Linux is a great jumping-off place. I disabled the PMIC through U-Boot’s menuconfig (and consequently, the AXP GPIOs and poweroff command), and added a dummy regulator for the SDMMC port in the DTS file, but otherwise had no issues booting into Linux. I had the card-detect pin connected properly and didn’t have a chance to test whether or not the boot ROM will even attempt to boot from MMC0 if the CD line isn’t low.
Once you’re booted up, there’s not much to report. It’s an entirely stock Linux experience. Mainline support for the Allwinner A33 is pretty good — better than almost every other Allwinner part — so you shouldn’t have issues getting basic peripherals working.
Whenever I have to modify an Allwinner DTS file, I’m reminded how much nicer these are than basically every other part in this review. They use simple string representations for pins and functions, with no magic bits to calculate or datasheet look-ups for alternate-function mapping; the firmware engineer can modify the DTS files looking at nothing other than the part symbol on the schematic.

Texas Instruments AM335x/AMIC110
The Texas Instruments Sitara AM335x family is TI’s entry-level range of MPUs introduced in 2011. These come in 300-, 600-, 800-, and 1000-MHz varieties, and two features — integrated GPU and programmable real-time units (PRU) — set them apart from other parts reviewed here.
I reviewed the 1000-MHz version of the AM3358, which is the top-of-the-line SGX530 GPU-enabled model in the family. From TI Direct, this part rings in at $11.62 @ 100 qty, which is a reasonable value given that this is one of the more featureful parts in the roundup.
These Sitara parts are popular — they’re found in Siglent spectrum analyzers (and even bench meters), the (now defunct) Iris 2.0 smart home hub, the Sense Energy monitor, the Form 2 3D printer, plus lots of low-volume industrial automation equipment.
In addition to all the AM335x chips, there’s also the AMIC110 — a newer, cheaper version of the AM3352. This appears to be in the spirit of the i.MX 6ULZ — a stripped-down version optimized for low-cost IoT devices. I’m not sure it’s a great value, though: while having identical peripheral complements, the i.MX 6ULZ runs at 900 MHz while the AMIC110 is limited to 300. The AMIC110 is also 2-3 times more expensive than the i.MX 6ULZ. Hmm.
There’s a standard complement of comms peripherals: three MMC ports (more than every other part except the A33), 6 UARTs, 3 I2Cs, 2 SPI, 2 USB HS and 2 CAN peripherals. The part has a 24-bit parallel RGB LCD interface, but oddly, it was the only device in this round-up that lacks a parallel camera interface.((Apparently Radium makes a parallel camera board for the BeagleBone that uses some sort of bridge driver chip to the GPMC, but this is definitely a hack.))
The Sitara has some industrial-friendly features: an 8-channel 12-bit ADC, three PWM modules (including 6-output bridge driver support), three channels of hardware quadrature encoder decoding, and three capture modules. While parts like the STM32MP1 integrate a Cortex-M4 to handle real-time processing tasks, the AM335x uses two proprietary-architecture Programmable Real-Time Unit (PRU) for these duties.
I only briefly played around with this capability, and it seems pretty half-baked. TI doesn’t seem to provide an actual peripheral library for these parts — only some simple examples. If I wanted to run something like a fast 10 kHz current-control loop with a PWM channel and an ADC, the PRU seems like it’d be perfect for the job — but I have no idea how I would actually communicate with those peripherals without dusting off the technical reference manual for the processor and writing the register manipulation code by hand.
It seems like TI is focused pretty heavily on EtherCAT and other Industrial Ethernet protocols as application targets for this processor; they have PRU support for these protocols, plus two gigabit Ethernet MACs (the only part in this round-up with that feature) with an integrated switch.
A huge omission is security features: the AM335x has no secure boot capabilities and doesn’t support TrustZone. Well, OK, the datasheet implies that it supports secure boot if you engage with TI to obtain custom parts from them — presumably mask-programmed with keys and boot configuration. Being even more presumptuous, I’d hypothesize that TI doesn’t have any OTP fuse technology at their disposal; you’d need this to store keys and boot configuration data (they use GPIO pins to configure boot).
Hardware Design
When building up schematics, the first thing you’ll notice about the AM335x is that this part is in dire need of some on-chip voltage regulation (in the spirit of the i.MX 6 or STM32MP1). There are no fewer than 5 different voltages you’ll need to supply to the chip to maintain spec: a 1.325V-max VDD_MPU supply, a 1.1V VDD_CORE supply, a 1.35 or 1.5V DDR supply, a 1.8V analog supply, and a 3.3V I/O supply.
My first effort was to combine the MPU, CORE, and DDR rails together as I did with the previous two chips. However, the AM335x datasheet has quite specific power sequencing requirements that I chose to ignore, and I had issues getting my design to reliably startup without some careful sequencing (for discrete-regulator inspiration, check out Olimex’s AM335x board).
I can’t recommend using discrete regulators for this part: my power consumption is atrocious and the BOM exploded with the addition of a POR supervisor, a diode, transistor, different-value RC circuits — plus all the junk needed for the 1.35V buck converter and two linear regulators. This is not the way you should be designing with this part — it really calls for a dedicated PMIC that can properly sequence the power supplies and control signals.
Texas Instruments maintains an extensive PMIC business, and there are many supported options for powering the AM335x — selecting a PMIC involves figuring out if you need dual power-supply input capability, Lithium-Ion battery charging, and extensive LDO or DC/DC converter additions to power other peripherals on your board. For my break-out board, I selected the TPS65216, which was the simplest PMIC that Texas Instruments recommended using with the AM335x. There’s an app notes suggesting specific hook-up strategies for the AM335x, but no exact schematics were provided. In my experience, even the simplest Texas Instruments power management chips are overly complicated to design around, and I’m not sure I’ve ever nailed the design on the first go-around (this outing was no different).
There’s also a ton of control signals: in addition to internal 1.8V regulator and external PMIC enable signals — along with NMI and EXT_WAKEUP input — there are no fewer than three reset pins (RESET_INOUT, PWRONRST, and RTC_PWRONRST).

In addition to power and control signals, booting on the Sitara is equally clunky. There are 16 SYSBOOT signals multiplexed onto the LCD data bus used to select one of 8 different boot priority options, along with main oscillator options (the platform supports 24, 25, 26 and 19.2 MHz crystals). With a few exceptions, the remaining nine pins are either “don’t care” or required to be set to specific values regardless of the options selected. I like the flexibility to be able to use 25 MHz crystals for Ethernet-based designs (or 26 MHz for wireless systems), but I wish there was also a programmable fuse set or other means of configuring booting that doesn’t rely on GPIO signals.
Overall, I found that power-on boot-up is much more sensitive on this chip than anything I’ve ever used before. Misplacing a 1k resistor in place of a 10k pull-up on the processor’s reset signal caused one of my prototypes to fail to boot — the CPU was coming out of reset before the 3.3V supply had come out of reset, so all the SYSBOOT signals were read as 0s.
Other seemingly simple things will completely wreak havoc on the AM335x: I quickly noticed my first prototype failed to start up whenever I have my USB-to-UART converter attached to the board — parasitic current from the idle-high TX pin will leak into the processor’s 3.3V rail and presumably violate a power sequencing spec that puts the CPU in a weird state or something. There’s a simple fix — a current-limiting series resistor — but these are the sorts of problems I simply didn’t see from any other chip reviewed. This CPU just feels very, very fragile.
Things don’t get any better when moving to DDR layout. TI opts for a non-standard 49.9-ohm ZQ termination resistance, which will annoyingly add an entirely new BOM line to your design for no explicable reason. The memory controller pinout contains many crossing address/command nets regardless of the memory IC orientation, making routing slightly more annoying than the other parts in this review. And while there’s a downloadable IBIS model, a warning on their wiki states that “TI does not support timing analysis with IBIS simulations.” As a result, there’s really no way to know how good your timing margins are.
That’s par for the course if you’re Allwinner or Rockchip, but this is Texas Instruments — their products are used in high-reliability aerospace applications by engineers who lean heavily on simulation, as well as in specialty applications where you can run into complex mechanical constraints that force you into weird layouts that work on the margins and should be simulated.
There’s really only one good thing I can say about the hardware design: the part has one of the cleanest ball-outs I saw in this round-up. The power supply pins seem to be carefully placed to allow escaping on a single split plane — something that other CPUs don’t handle as well. There’s plenty of room under the 0.8mm-pitch BGA for normal-sized 0402 footprints. Power pins are centralized in the middle of the IC and all I/O pins are in the outer 4 rows of balls. Peripherals seem to be located reasonably well in the ball-out, and I didn’t encounter many crossing pins.

Software Design
Texas Instruments provides a Yocto-derived Processor SDK that contains a toolchain plus a prebuilt image you can deploy to your EVK hardware. They have tons of tools and documentation to help you get started — and you’ll be needing it.
Porting U-Boot to work with my simple breakout board was extremely tedious. TI doesn’t enable early serial messages by default, so you won’t get any console output until after your system is initialized and the SPL turns things over to U-Boot Proper, which is way too late for bringing up new hardware. TI walks you through how to enable early debug UART on their Processor SDK documentation page, but there’s really no reason this should be disabled by default.
It turns out my board wasn’t booting up because it was missing an I2C EEPROM that TI installs on all its EVKs so U-Boot can identify the board it’s booting from and load the appropriate configuration. This is an absolutely bizarre design choice; for embedded Linux developers, there’s little value in being able to use the same U-Boot image in different designs — especially if we have to put an EEPROM on each of our boards for this sole purpose.

This design choice is the main reason that makes the AM335x U-Boot code so clunky to work through — rather than have a separate port for each board, there’s one giant board.c file with tons of switch-case statements and conditional blocks that check if you’re a BeagleBone, a BeagleBone Black, one of the other BeagleBone variants (why are there so many?), the official EVM, the EVM SK, or the AM3359 Industrial Communication Engine dev board. Gosh.
In addition to working around the EEPROM code, I had to hack the U-Boot environment a bit to get it to load the correct DTB file (again, since it’s a universal image, it’s built to dynamically probe the current target and load the appropriate DTB, rather than storing it as a simple static environmental variable).
While the TPS65216 is a recommended PMIC for the AM335x, TI doesn’t actually have built-in support for it in their AM335x U-Boot port, so you’ll have to do a bit of copying and pasting from other ports in the U-Boot tree to get it running — and you’ll have to know the little secret that the TPS65216 has the same registers and I2C address as the older TPS65218; that’s the device driver you’ll have to use.
Once U-Boot started booting Linux, I was greeted by…. nothing. It turns out early in the boot process the kernel was hanging on a fault related to a disabled RTC. Of course, you wouldn’t know that, since, in their infinite wisdom, TI doesn’t enable earlyprintk either, so you’ll just get a blank screen. At this point, are you even surprised?

Once I got past that trouble, I was finally able to boot into Linux to do some benchmarking and playing around. I didn’t encounter any oddities or unusual happenings once I was booted up.
I’ve looked at the DTS files for each part I’ve reviewed, just to see how they handle things, and I must say that the DTS files on the Texas Instruments parts are awful. Rather than using predefined macros like the i.MX 6 — or, even better, using human-readable strings like the Allwinner parts — TI fills the DTS files with weird magic numbers that get directly passed to the pinmux controller. The good news is they offer an easy-to-use TI PinMux Tool that will automatically generate this gobbledygook for you. I’m pretty sure a 1 GHz processor is plenty capable of parsing human-readable strings in device tree files, and there are also DT compiler scripts that should be able to do this with some preprocessor magic. They could have at least had pre-defined macros like NXP does.
STM32MP1
The STM32MP1 is ST’s entry into Cortex-A land, and it’s anything but a tip-toe into the water. These Cortex-A7 parts come in various core count / core speed configurations that range from single-core 650 MHz to dual-core 800 MHz + Cortex-M4 + GPU.
These are industrial controls-friendly parts that look like high-end STM32F7 MCUs: 29 timers (including the usual STM32 advanced control timers and quadrature encoder interfaces), 16-bit ADCs running up to 4.5 Msps, DAC, a bunch of comms peripherals (plenty of UART, I2C, SPI, along with I2S / SPDIF).

But they also top out the list of parts I reviewed in terms of overall MPU-centric peripherals, too: three SDIO interfaces, a 14-bit-wide CSI, parallel RGB888-output LCD interface, and even a 2-lane MIPI DSI output (on the GPU-enabled models).
The -C and -F versions of these parts have Secure Boot, TrustZone, and OP-TEE support, so they’re a good choice for IoT applications that will be network-connected.
Each of these processors can be found in one of four different BGA packages. For 0.8mm-pitch fans, there are 18x18mm 448-pin and 16x16mm 354-pin options. If you’re space-constrained, ST makes a 12×12 361-pin and 10x10mm 257-pin 0.5mm-pitch option, too. The 0.5mm packages have tons of depopulated pads (and actually a 0.65mm-pitch interior grid), and after looking carefully at it, I think it might be possible to fan-out all the mandatory signals without microvias, but it would be pushing it. Not being a sadomasochist, I tested the STM32MP157D in the 354-pin 0.8mm-pitch flavor.
Hardware Design
When designing the dev board for the STM32MP1, ST really missed the mark. Instead of a Nucleo-style board for this MCU-like processor, ST offers up two fairly-awful dev boards: the $430 EV1 is a classic overpriced large-form-factor embedded prototyping platform with tons of external peripherals and connectors present.
But the $60 DK1 is really where things get offensive: it’s a Raspberry Pi form-factor SBC design with a row of Arduino pins on the bottom, an HDMI transmitter, and a 4-port USB hub. Think about that: they took a processor with almost 100 GPIO pins designed specifically for industrial embedded Linux work and broke out only 46 of those signals to headers, all to maintain a Raspberry Pi / Arduino form factor.
None of the parallel RGB LCD signals are available, as they’re all routed directly into an HDMI transmitter (for the uninitiated, HDMI is of no use to an embedded Linux developer, as all LCDs use parallel RGB, LVDS, or MIPI as interfaces). Do they seriously believe that anyone is going to hook up an HDMI monitor, keyboard, and mouse to a 650 MHz Cortex-A7 with only 512 MB of RAM and use it as some sort of desktop Linux / Raspberry Pi alternative?
Luckily, this part was one of the easiest Cortex-A7s to design around in this round-up, so you should have no issue spinning a quick prototype and bypassing the dev board altogether. Just like the i.MX 6, I was able to power the STM32MP1 with nothing other than a 3.3V and 1.35V regulator; this is thanks to several internal LDOs and a liberal power sequencing directive in the datasheet.((With one caution I glanced past: the 3.3V USB supply has to come up after the 1.8V supply does, which is obviously impossible when using the internal 1.8V regulator. ST suggests using a dedicated 3.3V LDO or P-FET to power-gate the 3.3V USB supply.))
There’s a simple three-pin GPIO bootstrapping function (very similar to STM32 MCUs), but you can also blow some OTP fuses to lock in the boot modes and security features. Since there are only a few GPIO pins for boot mode selection, your options are a bit limited (for example, you can boot from an SD card attached to SDMMC1, but not SDMMC2), though if you program booting through OTP fuses, you have the full gamut of options.
The first thing you’ll notice when fanning out this chip is that the STM32MP1 has a lot of power pins — 176 of them, mostly concentrated in a massive 12×11 grid in the center of the chip. This chip will chew threw almost 800 mA of current when running Dhrystone benchmarks across both cores at full speed — perhaps that explains the excessive number of power pins.
This leaves a paltry 96 I/O pins available for your use — fewer than any other BGA-packaged processor reviewed here (again, this is available in a much-larger 448-pin package). Luckily, the pin multiplexing capabilities on this chip are pretty nuts. I started adding peripherals to see what I could come up with, and I’d consider this the maxed-out configuration: Boot eMMC, External MicroSD card, SDIO-based WiFi, 16-bit parallel RGB LCD interface, RMII-based Ethernet, 8-bit camera interface, two USB ports, two I2C buses, SPI, plus a UART. Not bad — plus if you can ditch Ethernet, you can switch to a full 24-bit-wide display.
Software
These are new parts, so software is a bit of a mess. Officially, ST distributes a Yocto-based build system called OpenSTLinux (not to be confused with the older STLinux distribution for their old parts). They break it down into a Starter package (that contains binaries of everything), a Developer package (binary rootfs distribution + Linux / U-Boot source), and a Distribution package, that lets you build everything from source using custom Yocto layers.
The somewhat perplexingly distribute a Linux kernel with a zillion patch files you have to apply on top of it, but I stumbled upon a kernel on their GitHub page that seems to have everything in one spot. I had issues getting this kernel to work, so until I figure that out, I’ve switched to a stock kernel, which has support for the earlier 650 MHz parts, but not the “v2” DTS rework that ST did when adding support for the newer 800 MHz parts. Luckily, it just took a single DTS edit to support the 800 MHz operating speed

ST provides the free STM32CubeIDE Eclipse-based development environment, which is mainly aimed at developing code for the Cortex-M4. Sure, you can import your U-Boot ELF into the workspace to debug it while you’re doing board bring-up, but this is an entirely manual process (to the confusion and dismay of many users on the STM32 MPU forum).
As usual, CubeIDE comes with CubeMX, which can generate init code for the Cortex-M4 core inside the processor — but you can also use this tool to generate DTS files for the Cortex-A7 / Linux side, too((No, ST does not have a bare-metal SDK for the Cortex-A7)).
If you come from the STM32 MCU world, Cube works basically the same when working on the integrated M4, with an added feature: you can define whether you want a peripheral controlled by the Cortex-A7 (potentially restricting its access to the secure area) or the Cortex-M4 core. I spent less than an hour playing around with the Cortex-M4 stuff, and couldn’t actually get my J-Link to connect to that core — I’ll report back when I know more.
Other than the TI chip, this is the first processor I’ve played with that has a separate microcontroller core. I’m still not sold on this approach compared to just gluing a $1 MCU to y our board that talks SPI — especially given some less-than-steller benchmark results I’ve seen — but I need to spend more time with this before casting judgment.

If you don’t want to mess around with any of this Cube / Eclipse stuff, don’t worry: you can still write up your device tree files the old-fashioned way, and honestly, ST’s syntax and organization is reasonably good — though not as good as the NXP, Allwinner, or Rockchip stuff.

Rockchip RK3308
Anyone immersed in the enthusiast single-board computer craze has probably used a product based around a Rockchip processor. These are high-performance, modern 28nm heterogenous ARM processors designed for tablets, set-top boxes, and other consumer goods. Rockchip competes with — and dominates — Allwinner in this market. Their processors are usually 0.65mm-pitch or finer and require tons of power rails, but they have a few exceptions. Older processors like the RK3188 or RK3368 come in 0.8mm-pitch BGAs, and the RK3126 even comes in a QFP package and can run from only 3 supplies.
I somewhat haphazardly picked the RK3308 to look at. It’s a quad-core Cortex-A35 running at 1.3 GHz obviously designed for smart speaker applications: it forgoes the powerful camera ISP and video processing capabilities found in many Rockchip parts, but substitutes in a built-in audio codec with 8 differential microphone inputs — obviously designed for voice interaction. In fact, it has a Voice Activity Detect peripheral dedicated just to this task. Otherwise, it looks similar to other generalist parts reviewed: plenty of UART, SPI, and I2C peripherals, an LCD controller, Ethernet MAC, dual SDIO interfaces, 6-channel ADC, two six-channel timer modules, and four PWM outputs.
Hardware
Unlike the larger-scale Rockchip parts, this part integrates a power-sequencing controller, simplifying the power supplies: in fact, the reference design doesn’t even call for a PMIC, opting instead for discrete 3.3-, 1.8-, 1.35- and 1.0-volt regulators. This adds substantial board space, but it’s plausible to use linear regulators for all of these supplies (except the 1.35V and 1.0V core domains). This part only has a 16-bit memory interface — this puts it into the same ballpark as the other parts reviewed here in terms of DDR routing complexity.
This is the only part I reviewed that was packaged in a 0.65mm-pitch BGA. Compared to the 0.8mm-pitch parts, this slowed me down a bit while I was hand-placing, but I haven’t run into any shorts or voids on the board. There are a sufficient depopulation of balls under the chip to allow comfortable routing, though I had to drop my usual 4/4 rules down to JLC’s minimums to be able to squeeze everything through.
Software
For a Chinese company, Rockchip has a surprisingly good open-source presence for their products — there are officially-supported repos on GitHub for Linux, U-Boot, and other projects, plus a Wiki with links to most of the relevant technical literature.
Once you dig in a bit, things get more complicated. Rockchip has recently removed their official Buildroot source tree (and many other repos) from GitHub, but it appears that one of the main developers at Rockchip is still actively maintaining one.
While Radxa (Rock Pi) and Pine64 both make Rockchip-powered Single-Board Computers (SBCs) that compete with the Raspberry Pi, these companies focus on desktop Linux software and don’t maintain Yocto or Buildroot layers.
Firefly is probably the biggest maker of Rockchip SoMs and dev boards aimed at actual embedded systems development. Their SDKs look to lean heavily on Rockchip’s internally-created build system. Remember that these products were originally designed to go into Android devices, so the ecosystem is set up for trusted platform bootloaders with OTA updates, user-specific partitions, and recovery boot modes — it’s quite complicated compared to other platforms, but I must admit that it’s amazing how much firmware update work is basically done for you if you use their products and SDKs.
Either way, the Firefly RK3308 SDK internally uses Buildroot to create the rootfs, but they use their internal scripts to cross-compile the kernel and U-Boot, and then use other tools to create the appropriate recovery / OTA update packages ((Buildroot’s genimage tool doesn’t support the GPT partition scheme that appears necessary for newer Rockchip parts to boot)). Their SDK for the RK3308 doesn’t appear to support creating images that can be written to MicroSD cards, unfortunately.
There’s also a meta-rockchip Yocto layer available that doesn’t seem to have reliance on external build tools, but to get going a bit more quickly, I grabbed the Debian image that the Radxa threw together for the Rock Pi S folks threw together, tested it a bit, and then wiped out the rootfs and replaced it with a rootfs generated from Buildroot.
Benchmarks
I didn’t do nearly as much benchmarking as I expected to do, mostly because as I got into this project, I realized these parts are so very different from each other, and would end up getting used for such different types of projects. However, I’ve got some basic performance and power measurements that should help you roughly compare these parts; if you have a specific CPU-bound workload running on one of these chips, and you want to quickly guess what it would look like on a different chip, this should help get you started.
Dhrystone Scores (DMIPS)- Single Core
- All Cores
- Single Core
- All Cores
DMIPS Power Consumption (mA)
DMIPS/mA
Dhrystone Benchmarks
Dhrystone is a small integer benchmark program that usually runs entirely in CPU cache; indeed, in my tests, changing SDRAM operating frequencies had no effect on the Dhrystone score. The Dhrystone benchmark reports its results in Dhrystones/sec, but we usually divide this number by 1757 (the number of Dhrystones per second obtained on a VAX 11 — a 1 MIPS machine) to compute the Dhrystone MIPS (DMIPS) score.
I ran this benchmark on all processors reviewed — most of which are single-core. On the dual-core STM32MP1 and quad-core A33 / RK3308, I ran multiple copies of the benchmark and added their scores.
Since all of these processors have bog-standard off-the-shelf Arm core implementations, this benchmark is somewhat silly to do, as you should be able to simply compute the DMIPS score based on the core design and clock speed. Yet, there are actually some variations in the data that come from different Linux versions (why is the 900 MHz i.MX8ULL faster than the 1000 MHz AM335x and V3s?) and possibly some over-aggressive thermal throttling on the RK3308 (the single-core DMIPS score is much higher than everyone else’s — as you’d expect from a 1.3 GHz Cortex-A35 — yet the all-core speed is much less than 4x the single-core speed).((By the way, I’d love to have an operating systems/architecture guru explain to me in the comments why an 216 MHz STM32F746 advertises itself at 462 DMIPS —a score that the i.MX 6UL’s 528 MHz Cortex-A7 can just barely hit. I know that running a Linux kernel in the background introduces overhead, but why do the dual- and quad-core chips scale linearly? You’d think their single-core performance would be higher than the multi-core, since the kernel could essentially dedicate a second core to running the benchmark and keep everything else on the first core.))
There’s obviously a huge performance disparity between a 300 MHz ARM9 and a quad-core 1.5 GHz Cortex-A53, but the bigger takeaway is that there are serious performance increases from simply migrating from ARM9 to Cortex-A5 to Cortex-A7 to Cortex-A35 (it’s not just marketing hype). The SAMA5 scored 1.75 times the score that the SAM9X60 did, while only running at 83% the clock speed. Meanwhile, the 528 MHz Cortex-A7 inside the i.MX 6UL is clocked only 6% faster than the 500 MHz Cortex-A5-equipped SAMA5, yet was 43% faster. And if you’ve got a floating-point workload, these differences would only magnify.
Power Consumption
To add a bit more context to the Dhrystone benchmark, I took some current measurements of each board under load.
My current consumption measurements are pretty haphazard; I was mostly just interested to see when LDOs were appropriate for core supplies. For the boards with LDOs, I simply report the measured current flowing into the 5V rail (which goes through the regulators into the core, the memory, the IO, the flash storage device, and some quiescent current into the regulator itself). The theory is that under a Dhrystone benchmark, the amount of current consumed by the core is going to overwhelm the others.
For the boards with buck converters on the core supplies, I’m even more devious: I measured the total 5V current, then divided by the conversion ratio and multiplied by 90% (the estimated efficiency of the converter). You’d be surprised how close I get to datasheet numbers using this ridiculously-inaccurate approach. Basically, all of these numbers are going to be high — I’d bet if I were actually measure core supply rails, I’d see a 10-20 mA reduction across the board.
Looking at the data you’ll see a solid increase in power consumption as you increase clock speed and/or core count (obviously), but there are some more nuanced things going on:
- The F1C100s has strikingly good power figures — matching the 528-MHz Cortex-A7-endowed i.MX 6UL in terms of efficiency (though certainly not performance). Its 40 nm process appears to be a smaller technology node than what the NUC980, SAM9X60, and SAMA5D27 use.
- I wouldn’t trust these AM335x power figures — I was too lazy to hook up a separate VDD_CORE supply, so I’m slaving it off the 1.35V CDD_MPU / DDR rail. A sycophantic engineer using a TI-approved PMIC would likely see much better numbers.
- When you move up to the Cortex-A7 or Cortex-A35, you don’t necessarily get any more MHz/mA — instead, you get more DMIPS/MHz, so they consequently perform more DMIPS/mA, too.
- Are LDOs reasonable choices to power any of these cores? Assuming 180 K/W thermal resistance of a SOT25 LDO and an allowable 125K delta, you want to stay under 700 mW of dissipation, maximum. That’s about 180 mA maximum output current if regulating from 5V to 1.2V. The NUC980, SAM9X60 and SAMA5D27 are getting pretty close, though again, these estimates are high.
Node.js Polymer Shop Benchmark (seconds)- Startup
- Cold Load
- Warm Reload
- Startup
- Cold Load
- Warm Reload
Node.js Express benchmark
Typically, these sorts of processors would end up in devices that make behind-the-scenes requests to cloud-based systems using lightweight protocols like MQTT— they would not be directly handling user requests. But with growing interest in decentralizing smart devices, I wondered if the connected gadgets around our homes could self-host rich web applications that we could use to directly interact with them. I used the Polymer Project’s sample e-commerce PWA, called Shop, to test things out. This isn’t your typical WiFi router config page — rather, it’s a modern Node.js-based web application that weighs in at almost 600 MB once all the dependencies are installed((These aren’t all used at runtime.)).
Using an aggressive test case like this helps to magnify differences between these platforms — in practice, you would likely build out a much slimmer application. I recorded the time it took to start up the app, along with the time it took to fully load the home page of the app in two cases: initial start (the first time the homepage is requested), and a warm reload (reloading the homepage after the server has already cached the data). I cleared the browser cache to make sure the warm reload was actually hitting the server.
This benchmark was a bit clunky to perform accurately, and there’s really no reason to test a whole field of different Cortex-A7s, so I only picked a few processors from this round-up for the benchmark. Node.js dropped support for ARM9 several years ago, so the Atmel SAMA5D27 was the lowest-end processor I could perform this benchmark on. I also selected the 900-MHz i.MX 6ULL, along with the Rockchip RK3308 and the Allwinner A33 — the latter was tested at both DDR3-800 and DDR3-1600 speeds.
On the quad-core A7 part running at DDR3-1600 memory (Allwinner A3), I noticed CPU usage maxed out at 38%, which indicates the workload is lightly threaded.
Every part except the Atmel part had ample RAM (512-2048 MB), and the Atmel part had 128 MB with most if it free (there were no reserved memory segments in the kernel configuration). The performance differences seem to reflect CPU and I/O bandwidth, not paging / caching issues from having limited RAM.
As you can see, the first load is where these processors struggle the most, sometimes taking more than three and a half minutes (!!!) to load the page. The good news is that if you can periodically preload the page (with a cron job or something), warm reloads can get down to the sub-2-second range on nicer parts, even with a web application as large as this one.
I’m glad I threw in different memory speeds: you can clearly see that the faster RAM helps load pages more quickly, but the faster RK3308 (with slower DDR3-1066 memory), is still noticeably faster than the A33 running at DDR3-1600 when starting up (where the initial application is JIT compiled).
Many of you are looking at the Ethernet PHY on the 1 GHz V3s and wondering about using it as a web server. Would it have similar performance to the i.MX 6? I restarted the i.MX 6 with mem=64M to simulate what it would be like to run this on something like a V3s and it…. well, wasn’t great. I waited around for more than 20 minutes for the app to start-up before I gave up((This is obviously way more complicated than I’m letting on, since I realized the i.MX 6 defconfig for the kernel reserved 32M of memory for CMA and the kernel image itself was quite large.)). Bumping it up to 128MB helped a bit, but moving up to 256M seemed to enable me to duplicate the original results I got.
Discussion
Nuvoton NUC980
This SIP was easier to design hardware around than every other part reviewed here, requiring the fewest (and cheapest) external components and using an easy-to-pencil-solder 0.65mm-pitch 64-pin QFP package and SPI NOR flash chip. Without mainline Linux / Buildroot / U-Boot support, you’re left to follow Nuvoton’s carefully-written BSP manual and pull sources from their GitHub page. Because the out-of-the-box configuration targets an initrd rootfs, it’s a pain to use for development, so plan to spend some time switching things over to an actual persistent filesystem.
Because of all this, I think this chip is great for embedded Linux firmware developers who might be less comfortable with hardware and want to get their hands dirty with some basic PCB design and prototyping. I think the larger versions of the NUC980 are less interesting, and mostly overlap territory held by the SAM9X60, which is almost as easy to design hardware around, has similar pricing, and runs twice the speed while offering a more generalist peripheral set (like an LCD controller) as well as the secure boot capabilities most IoT product specifications call for these days.
There are definitely corner-cases for the NUC980, though: I hate ultra-fine 0.4mm-pitch QFPs, but many seem to prefer them over BGAs. The NUC also has tons of USB host ports, plus a better collection of communication peripherals than most other parts reviewed here. Just keep in mind that the NUC980’s slow ARM9 core is really designed for basic C/C++ IoT gateway-type projects, potentially with some industrial I/O and control-oriented tasks.
Allwinner F1C200s
This is a tiny, cheap SIP that’s easy to design hardware around, slightly harder to get booted, and definitely fun to play with. It’s far from a general-purpose do-anything part. With only one MMC port (that you’ll likely tie up with a WiFi module), it’s limited to SPI flash booting. It can’t decode video (yet), so using it for multimedia is out of the question.
While you might want to grab it for a basic HMI project, the sunxi-fel USB loader software can only access the first 16MB of your SPI flash, which limits the size of your rootfs — Qt development is essentially impossible, so you’ll need to use much tinier graphics libraries. Plus, the F1C200s lacks controls-oriented peripherals (no timers and just a single ADC input). All this, together, really limits the types of projects you can do with it.
Having said all that, if your application is light on peripherals and requirements, this low-cost part is worth considering — as long as you don’t mind ordering from Taobao and other Chinese vendors, as U.S.-based availability is completely nonexistent.
Microchip SAM9X60
With a normal DTS-based workflow, default SD-card booting, mainline Linux/U-Boot/Buildroot support in the works, good U.S. distributor availability, and an exceptionally easy package to design around, this SIP is the first part I’d feel comfortable recommending to a general audience of people new to embedded Linux firmware development but who also want easy-to-design hardware.
More advanced users will want to plot out their system architecture first and make sure this is really the right chip for the job — popular runtimes like Node.js and .NET Core simply will not run on an ARM9 processor, and at $8, it’s roughly the same price as an i.MX 6ULL + DDR, which is 5 times faster than the SAM9X60. This is also the lowest-end part I’d recommend doing modern GUI work in.
But for beginners, it’s reasonably good at running Python (and of course C/C++ code), there’s plenty of peripherals to dork around with, and the well-documented Secure Boot capabilities should help you get some practice with IoT security.
Microchip SAMA5D27
This is the highest-performing SIP available from U.S.-based vendors, so if you’re still nervous about taking the DDR plunge, this is about as good as it gets. It’s been around long enough to have good Linux support for all its peripherals and a decent ecosystem of documentation.
Having said that, I found it clunkier to design around (and get booted) than the SAM9X60. While it’s faster than the 9X60, it’s not stunningly so, and the low-cost Cortex-A7s like the i.MX 6ULL are cheaper and much more performant, while only being marginally more difficult to design around.
All told, the SAMA5D27 is sort of stuck in the middle of two different camps of processors — while offering middling performance and value. I still think it’s a reasonable entry into embedded Linux development, and one of the easiest-to-use parts I’d consider for an IoT-based application if I needed TrustZone / Secure Boot capability.
Allwinner V3s
The V3s is a specialty chip to pull out of your back pocket when the time arises. Hobbyists will find the LQFP package of the V3s a welcome sight, but I found the chip much more challenging to solder than the 0.8mm (or even 0.65mm) BGAs, so I can’t recommend it on those grounds.
The 64MB on-chip SDRAM is spacious enough for uClibc-based systems running C/C++ programs and simple Python scripts, but the memory restrictions impose a low ceiling when compared to the other Cortex-A-series parts in this round-up that will limit your ability to run large JIT-compiled applications written in frameworks like .NET Core or Node.js. Though, in my testing, basic Qt 5 apps — even written in QML — performed without issues.
With a built-in audio codec and ethernet PHY, this would be a great processor for use in a basic Internet-connected audio system. Just keep in mind that, like all the Allwinner parts, availability in the U.S. is spotty, and the (community-written) Linux drivers tend to be a tad bit buggier than usual.
NXP i.MX 6ULL
If you reject the premise of this blog post and instead want to commit to learning a single part family that you can reuse on a wide variety of projects, the i.MX 6ULL (and 6ULZ) should probably be at the top of your list. These generalist parts have a competent set of peripherals good for networked gadgets, industrial automation, and basic LCD interfacing, and also has secure-boot capabilities, plus support for TrustZone and OP-TEE.
Needing only two supply voltages and few external components, the i.MX 6 was the easiest discrete-DRAM part to design around in the round-up. The 0.8mm-pitch BGA offers 106 I/O in a small-but-not-too-small package.
In terms of software, with a few minor U-Boot hacks, you can get going quickly and forgo fuse-blowing and GPIO boot pin selection. These parts have been around forever, so they have good mainline support in U-Boot, Linux, and Buildroot for all their peripherals.
Starting at $2.68 for the ULZ, they’re also the cheapest application processors you can buy outside of China. Obtaining design help from NXP is relatively easy, and with wide availability from U.S., European, and Chinese vendors, managing production of an i.MX6-based design is trivial.
Allwinner A33
The A33 is a powerhouse part fighting with the newer RK3308 for the top-dog spot in the benchmarks. It’s also relatively straightforward to get working. There’s good mainline Linux support for most of the peripherals (but do your homework to verify they work properly), and U-Boot and Buildroot are both extremely easy to get going on this part.
But like the other two Allwinner chips reviewed, its peripheral set has huge gaps that reflect its pedigree as a tablet processor. It has a built-in audio codec, but no ADCs; RGB and MIPI DSI support, but no PWM outputs; three SDMMC ports, but no Ethernet MAC. You get the idea.
Having said that, some of the peripherals it does have go almost unmatched, like that MIPI DSI interface. MIPI DSI-interfaced LCDs are the standard today — if you’re stuck with a parallel RGB interface, it’s getting tougher to find high-quality IPS LCDs and basically impossible to find OLEDs. This is making most of the parts in this review irrelevant for modern consumer electronics development, as buyers are looking for better and better image quality from all their devices.
The usual supplier availability issues with Allwinner come into play; you’ll be buying samples off Taobao (or through horrendously-overpriced AliExpress / eBay listings). Chinese CMs shouldn’t have any issue obtaining parts once you go into production, though, and while these are older designs, Allwinner shows no signs of discontinuing them soon.
Texas Instruments AM335x
I was excited to try this part, since I see it in lots of gadgets. It has good U.S. availability, carries a reasonable price tag, and has similar features as other Cortex-A7 parts reviewed.
Unfortunately, at no point did I enjoy using this part. I ran into roadblock after roadblock, and most of them would have been completely eliminated if TI would have simplified their U-Boot codebase, enabled obvious defaults (like earlyprintk and printf support), and reworked the chip to simplify board design and reduce the fragility of the platform.
Once I finally did get everything working, it felt like a Pyrrhic victory: I had invested a ton of time and effort, all for a single-core Cortex-A7 that has some gaping holes in its feature set: no secure boot, no TrustZone, and not even a simple parallel camera interface. This part has its place in niche applications: if I were building out an industrial robot with EtherCAT support, this would be at the top of my list.
If you’re an obedient, studious engineer that will carefully follow datasheet guidelines and copy reference designs precisely, you will have no problem getting an AM335x-based design going. And since these parts are made by Texas Instruments, there’s always good technical support available via their E2E Forums and direct support connections while you’re working through design issues.
STMicroelectronics STM32MP157D
Introduced in 2019, the STM32MP1 is one of the newest parts in this review. With prices ranging from $8 to $17, these parts are quite a bit more expensive than some of the other parts I looked at, but they have some killer features that are hard to find anywhere else: an integrated Cortex-M4 microcontroller, a full set of microcontroller peripherals that looks to be ripped straight off an STM32H7-series processor, good interfacing options, and a dual-core 800 MHz architecture that makes it the third-fastest part in the round-up.
With all these features, this would be an excellent controls-oriented processor to look at if you have some prior embedded Linux experience and don’t mind working through some BSP kinks. They’re extremely easy to design hardware around and widely available; in time, these parts could become the Swiss Army Knife of embedded Linux development.
But until the software and documentation become a bit more stable, I think newbies should look elsewhere for their first embedded Linux project.
Rockchip RK3308
This part’s Cortex-A35 design puts it well above the rest of the field in terms of raw computing capability and overall efficiency. It may seem unfair to compare a part that came out in 2018 with parts that trace back to 2012 or 2013, but that’s the fault of these other vendors, who have largely focused their recent efforts on higher-end processors. NXP and Texas Instruments both make modern processors: the i.MX 8 and AM6x, but both are seriously expensive parts that you’re not going to find in entry-level gadgets.
The RK3308 is a good entry into their ecosystem. There’s no PMIC required (even their reference designs don’t use one), and the control signals are straightforward. It’s a 0.65mm-pitch part — a step below the 0.8mm-pitch BGAs everyone else in this round-up used — but I didn’t run into any problems during hand-placing.
But this is still not a part for the faint of heart: you’ll need 4 or 5 voltage supplies, fanning out the BGA is tedious, and you’ll be pushing your board house’s specs — they need to be able to hit 0.09mm trace/space and 0.2mm drill sizes.
On the software side, there’s no mainline Buildroot support for it (only Yocto support), and you’re not going to find a lot of English-language resources online in tutorial format (though the datasheet, TRM and example schematics are readily available). You’ll want to have some prior experience so you can read between the lines when necessary.
Honorable Mentions
While working on this, I looked at (and even played around with) some other parts that should be on your radar.
Azure Sphere MediaTek MT3620

The AI-Link WF-M620-RSC1 module from Seeed Studio uses the MediaTek MT3620
This is a highly-secure, preconfigured embedded Linux SOM (System On Module) that is designed for IoT applications. While other platforms support TrustZone and security measures to protect against reverse engineering, cloning, and firmware alterations, this is the only platform I’ve seen that ships with all these security features activated and preconfigured, and doesn’t allow them to be disabled. Before being able to deploy firmware, new devices must be provisioned — linked permanently to an Active Directory identity — which is stored in one-time-programmable memory. If you lose access to that AD identity, all your devices turn into paperweights. This is serious stuff.
Under the hood, this device is running Linux, but your application runs in a sandbox with custom secure APIs to the underlying hardware. From what I can tell, there’s no mechanism for writing kernel modules, so all device drivers execute within the context of your userspace application. Azure automatically delivers updates to the underlying Linux system, and you can push updates to your application to end devices through Azure as well.
I’ve played with this platform a bit and I’m perplexed I haven’t seen more buzz about it. Developing on it is dead-simple: after a few clicks, you’re connected to your WiFi network. A few more clicks, and you’re remotely debugging your code over WiFi. I found the custom userspace APIs for GPIO and communications interfaces are much less clunky to use than the standard Linux APIs.
Still, the biggest feature is that you get to write embedded Linux apps — with threads and memory management and all the good stuff — without having to screw around with setting up an embedded Linux system. It’s like getting your dessert without being forced to eat your peas and carrots first.
Oh, the hardware: it’s a 500 MHz Cortex-A7 with two 200-MHz Cortex-M4 real-time processors, built-in WiFi, and 5 MB of built-in SRAM (so it should actually have quite good sleep-mode power consumption compared to DRAM-based designs). It comes in a 12x12mm 164-pin dual-row QFN — likely only available in relatively high volumes directly from MediaTek. For low-volume work, Seeed Studio and Avnet make FCC-certified SOMs that are surprisingly inexpensive.
Renesas RZ/A
Renesas makes the RZ/A line of 400 MHz Cortex-A9 application processors that have on-chip integrated SRAM (yes, SRAM) of up to 10 MB with a 128-bit-wide interface. They have a special XIP (execute-in-place) Linux kernel that allows these parts to start up quickly. I imagine they would have excellent suspend-to-RAM current consumption, too. These come in monster 28x28mm QFP and more-reasonable BGA packages.
MediaTek MT7688AN (et al.)
MediaTek and Atheros make a ton of low-cost app processors that are designed for network appliances (typically routers). These are generally available in QFN, QFP, or coarse-pitch BGA packages targetting low-cost 4-layer PCB technology.
Because these processors integrate WiFi into them, you’ll see them used for IoT gadgets from companies like Belkin and TP-Link.
I actually bought some MediaTek MT7688AN chips, designed up a board, and built it up — intending to review the part for this review — but really struggled to get the hardware soldered up. The 0.5mm-pitch dual-row QFN was awful to work with, and after spending an entire afternoon hot-airing, removing, replacing, nudging, and resoldering, I gave up. The firmware situation is also a bit weird — I couldn’t find a Buildroot environment for this part, since these are usually developed in DD-WRT/OpenWRT, and it looked like the binaries these produced didn’t include a boot sector. I know that many of these devices have a “factory” area that stores calibration parameters, but I couldn’t figure out if this was one of those parts. I downloaded a pre-built OpenWRT build for the MT7688AN, which is the .bin file I used. These parts don’t appear to have a USB bootloader or any mechanism like that, so I had to manually attack to the SPI flash chip with my J-Link to program it. It wasn’t fun.
Anyway, I don’t think most people design PCBs around these raw parts anyway — the off-the-shelf SOMs are so ridiculously cheap (even ones that plausibly are FCC certified) that even relatively high-volume products I’ve seen in the wild use the solder-down modules (unless they’re space-constrained like the smart plugs mentioned above). These SOMs come with a factory image already burned into the chip, and once you boot it up, you can easily load different images.

Conclusions
This post was a lot of fun to put together. I went into this project with some previous experience with a couple of these processors — a bit over-confident with what I thought I knew — and ended up learning a ton.
I’ve blabbered on enough about Linux and these chips, so I wanted to leave you with a different thought entirely: This project re-affirmed the importance of practicing engineering (versus doing engineering). When you force yourself to get away from interesting domain-specific problem-solving and focus on the low-level mechanics of design work, in a repeated fashion, you end up building up muscle memory for things you thought you’d always have to think about.
By the time I got to the end of this project, working on the Rockchip RK3308, I was flying through things. I spent two hours researching, 20 minutes drawing the 355-pin schematic symbol, an hour routing the DDR3 bus, three hours fanning out the rest of the signals and routing power, and 30 minutes cleaning everything up.
When the boards came back, I put on some music, pasted them up, hand-placed everything, threw it on a hot plate, flipped it over to do the back side, and less than an hour later, I was booted up on a command prompt, sitting in front of a quad-core 1.3 GHz computer I made from $10 worth of parts, mounted on a $20 PCB.
That’s a far cry from where I was when I started doing this stuff years ago — cowering over my DDR layouts for days on end, wrapping my head around power plane designs, and constantly re-reading the datasheets, unsure of whether I had connected control lines properly.
I think everyone in this community — professional or hobbyist — tends to focus way too much on project outcomes. I hope that after reading this, you’re going to be tempted to drop one of these parts into your latest project, tossing in a bunch of other circuitry and plotting out tons of software work ahead.
But I also hope you consider practicing a bit first: design a little break-out for your processor, solder it up, and try it out. If you’re running into problems getting things working, consider doing the thing you’re never supposed to do: giving up and trying a different part. Compare and contrast. You’ll see patterns emerge as you get more familiar with how this stuff is done.
Continue working on your projects, but never be afraid to roll up your sleeves and commit to some quality practice time!
Nice!
Had a lot of fun using the NUC980 as my first microprocessor I’ve used. Thanks for loaning me your NUC980 IoT board lol
Wow, awesome!
Great stuff
This is awesome. It will certainly help newcomers like myself. I wish there could be a full tutorial series from designing a board from scratch focussed only on one BGA part with external RAM. It’s probably too much to ask for. Nevertheless..thanks for this!
Another terrific post!
Is it possible to publish the schematics and CAD/gerber files of some boards? Especially the i.MX6 and A33 are very interesting for me. I‘m not very familiar with routing high pin count BGAs but i‘m very interested in learning to design SoC boards.
(Sorry in case of bad english language, i‘m from germany and don‘t speak english natively)
Wow! Great article, and a very good conclusion. I would love to have you on my team.
Thank you so much for this great overview of all the relevant low-end Arm platforms!
I was suprised to see NUC980 make it to the list, since we removed the platform (arch/arm/mach-nuc900) from the kernel last year after it had been abandoned since around 2011. Without upstream support I would not want to use this for anything important, but if anyone reading this wants to help get it merged upstream and maintain it, please contact me.
F1C200s is also lacking upstream support, but there were patches for it a while ago and I hope someone will eventually get back to them. Everything else on your list is already well-maintained.
For memory capacity, I expect 512MB DDR3 to remain the practical maximum for 32-bit chips, for anything above that you end up paying a lot somewhere. With 4Gbit chips being the largest mass-market DDR3 option, anything larger needs either multiple chips (which you recommend against), expensive multi-die packages, or the rare 8Gbit dies that are getting hard to find.
I hope that LP-DDR4 solves this with capacities up to 64Gbit (8GB) per chip, but I don’t know what this means for the board layout. LP-DDR4 is supported on newer 64-bit Arm SoCs like Amlogic S905X2, TI AM654x, NXP i.MX8M, or the coming Allwinner and Rockchip parts that still lack mainline support (RK3530, H313, A133, …)
If you do get back to looking at non-Arm chips in the future , I’d love to find out how all of the ones here compare to things like the Mediatek MT7621DA or Ingenic X2000 SiPs, or one of the microcontrollers with Linux support (ST STM32F7, Kendryte K210, Nationalchip GX6605S, Espressif ESP32-S2).
Thanks for the fantastic note! I knew that Nuvoton has had an ARM9-based portfolio for a while (with the NUC970), but I had no idea it was ever upstreamed. The NUC980 is a new part, and they’ve been actively committing code to their 4.4-series branch. I couldn’t agree more that using a vendor’s old kernel that they “promise” to keep updated with security patches is a bit of a dead-end, though, and probably not something I’d design a serious product around.
Totally agree with the DDR3 comments, too; I hope the article gets some of that across. The multi-die packages are really great for prototyping because you can get that extra memory you might need during development without having to resort to a two-chip layout. If you need more than 512 MB of RAM with *any* of these parts in a production setting, after tuning, then your application is pretty unconventional, I’d think.
I forgot there was actually a submission for a modern port to the nuc970 a few years ago [1], but the author never posted a version 3 of the series after the initial comments. The code we removed was for the older nuc910, nuc950 and nuc960 chips [2] and used the original Winbond name. Unfortunately, that nuc980 BSP appears to be based on the older code rather than the cleaned up nuc970 version that would be a better choice for new upstream work.
[1] https://lore.kernel.org/linux-arm-kernel/[email protected]/
[2] https://lore.kernel.org/linux-arm-kernel/CAK8P3a3jjDh6aEVf0bBFYc=8GtB38kL6sWVZGJiUe427A7m2ng@mail.gmail.com/
One thing that should be watched out for especially with large die size DRAM is PCB footprint. Intelligent Memory had this problem when their chips were 10mm wide.
Yup! Definitely got burned by that during the first round of prototypes. I made a “universal” DDR3 footprint that has silkscreens for all the standard-size outlines to make hand-placement easier.
Just noticed that Micron have a new product now that should be interesting: https://www.micron.com/products/dram/ddr3-sdram/part-catalog/mt41k512m16vrn-107-it
There would be a lack of GPIO when you have done it, and it’s true what you say about analogue GPIO pins but you can interface parallel RGB displays to the Raspberry PI: https://www.raspberrypi.org/documentation/hardware/raspberrypi/dpi/README.md
Ooof, thanks for the correction! I’ve updated the article to remove mention of that.
Fantastic and comprehensive article. It removed many of my pre-conceived notions about vendors I would not have considered. Thank you for putting this together!
Thank you Jay for this nice review, very interesting!
I used the Allwinner V3s in our design, work like a charm.
Is it possible to provide links to the reference designs in this review?
Hi Michel,
Nice to hear you used the V3s. I was planning to get more involved with the V3s, got the Lichee board for starters, but was skeptical seeing that it did not have much support in the main stream. Your comment makes me get that chip out, take the dust off and begin working again. 🙂
Hi Royston,
Our FunKey S retro-gaming console is FOSS / Open Hardware. We already put previosu design files on HaD.io, and will release everything so anyone can tinker wit it.
Check https://www.funkey-project.com
To explain Poky (I think this is right): you mentioned OpenSTLinux as something produced by STM. Basically a specific version of a set of layers that you can use to build images for ST parts. Poky is like that – it’s a specific version of a set of layers that can be used to build images for a set of targets.
Yocto is really an organisational umbrella for some people producing stuff to enable building Linux distributions. They do a lot of work in a lot of places, but what they produce as their output (as the sum of all that work) is Poky. Poky is a set of layers that includes some provided by OpenEmbedded (a different project) and other places. You can use Poky on its own, it has support for some hardware, but more commonly a vendor will take it as a starting point, add some more layers and then call it (for example) OpenSTLinux.
Poky existed before Yocto as a way to solve the same basic problem you lay out of marshaling an image to a board. I do not know why Yocto hasn’t replaced Poky or if it was intended to replace it.
The S3 is a V3s in BGA package with 128MB of RAM. The two most interesting chips I see in the market right now are the RK1808 which includes a 5TOPS NPU, but it is around $11. Second is the Allwinner V831 – similar to the V3s plus 0.5TOPS NPU – $3. Both of these support 1080P cameras.
A very cost effective option is the RK3128. The RK3128 compares to the A64.
The RK1109 looks interesting, but I have not seen pricing.
Once tools for the V831 NPU are available I would expect the V831 to displace everyone working with the Kendryte K210. The V831 is Cortex-A7 and it includes h.264 encode/decode.
A variant on the V831 is the V833. It does not have on-chip DRAM but it supports 2K HD resolution. You can also attach a larger LCD to it.
The group I am working with is doing an Allwinner V536 design. The V536 supports 4K video and does not have a NPU. It is likely they will move onto the V833 when it is ready. The V536 and V831/3 use the same SDK.
Yes! Add to that the Allwinner X3, which is a SIP version of the A33 with I think has 128 MB of SDRAM. I have a pack of them sitting on my desk ready to play with. There are so many interesting SIPs and SoCs out there these days!
Thanks for the great article – super interesting read. I’ve been using the V3s on my latest project (and my first forte into embedded Linux – I was impressed with how easy it was to bring online — with a little help from Michel Stempin)
I was coming here to mention the Sochip X3 – would love to see the comparison to the A33 “mother” chip – its price and feature set makes it of particular interest to me – depending on current and operating temperature.
I’d also be interested in some of the other cheap SIP Chinese chips where we are seeing slow IP expatriation like the MStar MSC313e (V3s-esque in a QFN).
I also recently stumbled across the datasheet for Artinchip AIC800G3 (https://widora.io/_media/aic800g3_datasheet_v1.4.pdf – 4x A53 Cores, 1gb DDR4 SIP). Haven’t seen and taobao samples yet; but the datasheet is a few months old at most. Its written almost exactly like an Allwinner Datasheet, makes me think its like another Allwinner/Sochip branded IC deal. Specs wise it looks like the new Allwinner A100 in a SIP package.
I had ordered some samples from Sochip. The chip is real. around $9 per piece. But I am waiting for the linux bsp.
Hi Jay,
Do you know where I can get information on the Allwinner X3, I cannot find any?
Hi Jon, nice to see you here!
What about the RK3326? Looks interesting. Cannot find ref design for it though.
You can find RK3326 Aarch64 reference schematics in this link.
https://wiki.odroid.com/odroid_go_advance/start#documentations
That small gaming device uses a MIPI DSI LCD as well as SDIO WLAN interface.
Hi Jon
I was interested to see you mention a few parts with neural network hardware support as this is the area I’m interested in
Do you have some links you can share?
Thanks
-David
Allwinner chips are pretty interesting for the promise, if only wasn’t that hard to find clear or any information about them support. I wanted to make Gameboy like handheld with a V3s, based on the Funkey project, but I need a bigger screen, like 2.8″… People on Funkey project used a ST7789 display, but I wanted to know if it’s compatible with ili9341, for convenience. I know I could use a raspberry, but their prices now are way too high
This is not a post, but rather, almost a book about embedded Linux systems! Congratulations for your stamina and patience to write such a long piece. Thanks!
This is a fantastic article. Will you be making the PCB design files available?
really??
Saturday morning, my mobile chrome showed this article and I started reading and after 15 mins I thought… ‘when this gonna be end?’. I checked the location of the scrollbar. It was only 1/5. This cannot be just bookmarked but should be shared to my people. Great job! Thanks for your writting!
Great post, thanks! Note: the AM335x is erroneously referred to as a Cortex-A7 but it’s actually an A8
“The reduced setup/hold times make address/command length-tuning almost entirely unnecessary, and the reduced skew even helps with the bidrectional data bus signals.”
I think today’s 4Gbit DDR3 chips are more tolerant than DDR2 or even old 1Gbit DDR3 chips, right? One of the SoCs listed here still use DDR2.
Thanks Jay
Vefy informative. This is something I have always wanted to attempt, but the BGA and DDR tracks always puts me off.
How do you hand solder the 0.8mm BGA packages? You mention a hotplate.
Thx sir very useful, keep going!
Greetings from Italy
Hi! Thanks for the nice article, I learned a lot!
About the AM335x, did you happen to implement a clamping circuit for the 3.3V and 1.8V rails for power down sequence? https://www.ti.com/lit/ug/slvu731b/slvu731b.pdf?ts=1603039542170
I was wondering what are you thoughts on this requirement, that the difference between these rails should not exceed 2V during power down. Is this something that is common when powering down MPUs, or just a hacky fix from TI side?
Hi Jay, very nice and thorough post. The most comprehensive information gathered in one place I’ve seen so far.
In my opinion there are some good reasons why an integrated MCU on the SoC is better than an external MCU (STM32MP1). The main reason is that the M4 and A7 share the same resources, which has various benefits. One of them is that the M4 can have access to the DDR and it can share a memory blocks with the A7. In my post that you linked, I’ve used the direct mode, which means the M4 and A7 exchange data via OpenAMP, which is slow. Really slow. I guess it’s only usable as control IPC. But using the indirect buffer sharing mode you can share large buffers (e.g. Megabytes) between the M4 and A7 really fast. Use cases are usually fast data collection from the M4 and data visualization from the A7 using Qt.
Also updating the firmware on the MP1 is “somehow” easier. I mean, I just like the fact that you just load the bin on the /dev which points to the M4, but yeah DFU has pretty much the same effect. In case of DFU you just have a bit more complexity on the host A7’s OS in order to have a robust and secure update and also you need to have a secure bootloader on the external MCU, so the update over DFU is encrypted.
Generally, MP1 is really nice SoC, but very hard to configure and use in a project. The learning curve is too steep and I believe it requires a team of people in order to finished a new custom project in time.
As you’ve mentioned, for most cases I’m also favorable of using an external MCU. Most of the times I’m favorable also for just using spidev to control the MCU for simplicity, but there might be cases that I need to implement a custom driver to support the external MCU in the Linux kernel (e.g. https://www.stupid-projects.com/linux-and-the-i2c-and-spi-interfaces/).
It’s great to try everything for learning, but when it comes to implementation the simplest solution the best to go and definitely a win-win situation in terms of complexity, time and debugging.
Again, nice blog! You have a new follower.
Great article Ray. This is the best website I have seen, where you actually built the hardware and benchmarked them rather than throwing some comments from a datasheet. It helped me take a decision as to which chip I should lean towards for my low cost embedded system
Great article Jay. This is the best website I have seen, where you actually built the hardware and benchmarked them rather than throwing some comments from a datasheet. It helped me take a decision as to which chip I should lean towards for my low cost embedded system
Is there any plan to release your designs? I’m still a college student and I’m looking to get into embedded systems but it all seems so overwhelming! If not, could you point me in the right direction to find schematics and board designs to start picking apart?
I’ve linked to most EVKs available for these chips — check their corresponding documentation for the schematics. Depending on your propensity for gambling and your hardware design background, you might decide to copy them exactly, or you may only want to use the EVK files to double-check your design. I generally start in the chip’s datasheet in the electrical specifications section to plan out the power supply design. I try to identify the system/control signals (reset, NMI, XTAL, PWRON, etc) and check out the datasheet to see how they’re handled — cross-referencing the EVK schematics to double-check. Next, I hunt down the default boot source (usually a MicroSD/eMMC flash chip on MMC0, but sometimes SPI flash on smaller chips), and default console UART. You can cross-reference the EVK design files to see if you have any differences that seem peculiar.
Feel free to shoot me a DM on Twitter or start a thread (I’m @jaydcarlson) and we can dive into more nitty-gritty details!
Amazing.
Jesus Christ, man! I’m writing a 500 page book on this stuff for Packt. I will make sure to include a link to your primer. Respect.
Thanks for sharing this article, it has been truly inspiring.
I’ve considered whether I build my own system as I haven’t been completely happy with the existing single board computers on offer, but shied away from the complexity of laying out the high-speed buses needed. I’m working almost exclusively from a GNU/Linux based workstation, and have a strong preference for using open-source tools that do not hold my designs “hostage” to licensing. I’d be interested to know what design software you used for these boards or whether an open system like Kicad or GEDA might be viable?
I’ve had my run-in before with DDR2 timings my workplace bought some Technologic Systems TS-7670 SBCs (i.MX286-based) which shipped with a quite old Debian Wheezy-based OS with an ancient Linux 2.6.34 kernel (about 10 years old at the time). I managed to port U-Boot and kernel 4.0 running quite nicely on the 128MB version, but then the 256MB version fell over. Spent a good day or so scrutinising the two memory chip data sheets, trying to figure out what I was bumping up against, and on a whim, turned the speed in U-Boot down a fraction: success. There’s a fleet of these running that U-Boot and kernel in some residential towers at Barangaroo now, and I continue to keep a fork of both trees moderately up-to-date.
It’s reassuring to know that in fact, with some judicious part selection, memory interfacing can in fact be much more lenient than I previously feared. I might give it a shot some day when I have a day free. (hah!)
I had similar issues back in the day with an i.MX233. Luckily, I haven’t been able to produce a detectable error caused by trace skew issues. I think one of the advantages is that modern DDR3 chips are much faster than these memory controllers run at (It’s hard to find memory chips slower than -1600 or -1866 speed grades, which is twice as fast as most of these parts run at). This gives you shorter set-up/hold times and less jitter.
You should use whatever EDA software you feel most comfortable with. I did these in Altium, which I think is a lot more productive than other packages, but people do some amazing boards in KiCad. There’s no reason you couldn’t use something like that for an embedded Linux board! Good luck with your projects!
You had a question as to how the ST device can have a DMIPs number higher than the maximal clock rate. The device has multiple execution units which would allow issuing multiple instructions per clock cycle. You also have the ability to lock routines in zero wait state TCM memory. It is a bit of a marketing game but technically accurate for specific instruction sequences and limits the size to what you can fit into the TCM.
The other issues you run into with M7 devices, due to the high number of peripherals is GPIO mux conflicts and power consumption as you cannot really run all the peripherals at max clock and stay withing the bounds of the package thermals.
Anyway just a quick note.
Coming from the Microcontroller background, that is too much for me to handle . I think I will have to stick with RaspberryPi, at least, for now. I come from EE background and a newbie to the industry (2 yrs running). I have designed PCBs for the projects requiring microcontrollers only.
For the projects, that requires networking and threads, we use RaspberryPi. I have designed Raspi compatible HAT(Hardware Attached on Top)s with a cheap microcontroller (like ATMega328-pu) for extra PWMs, interfacing with analog sensors, and CAN controllers which Raspi doesn’t suppport natively.
However, sometimes it was extremely frustrating when Raspi wouldn’t support some ICs. For one particular project, I had to use SPI-interface enabled Microchip’s ENC424J600 ethernet controller chip. When I inquired about the issue, I got answers, but I was not able to understand more than half of them. In short, I understood that I had to rewrite the DTO and modify the kernel, which of course, I don’t know how to. I followed their instructions like copying and pasting commands but got stuck somewhere in the middle.
This made me interested in Embedded linux and came to this article. I think think I have a very long journey to design Embedded Linux capable boards.
Thank you, this is awesome article!
I have been searching for low-end arm comparison for long time. IMX6ULL and RK3308 scored great in your benchmark. I have experience of running Nodejs application on IMX6ULL. It only runs well with 256MB RAM (or above) and if you use Nodejs v12 (musl), the start-up time is noticeable decreased.
Was looking for IMX6ULL replacement, but from your article, it is still the best choice for low-power/high-performance chip. RK3308 is also interesting one. It seems that Radxa team is going to release SoM for the chip at 13.99$ (from their distributor’s site).
Wow, great article!
A minor nit, genimage in Buildroot does in fact support GPT partitions (genimage 11, part of Buildroot since 2019.08).
Thanks for this comprehensive disquisition..
Clearly, quite a lot to choose from for new designs.. I have had my fair share of experience with the V3S. Soldering isn’t all that bad with a good heat gun and some patience i must say.
The thing that bugged me with this particular Soc, though was that when i was trying to use it as the heart of my Linux based ‘Jamulus’ box (online repetition for musicians), I found out that it regularly dropped into a hardware-reboot when frame sizes went underneath 128. (above gives way to much latency) Might be related to the bugginess of the audiocodecs like you mentioned, maybe.. haven’t looked into it further.
BTW, What would you recommend to people looking to get into the embedded community a little more ?
Thanks again.
I’ve spent a full day reading this beautiful article and I ended up feeling much more comfortable with the idea of designing my own embedded linux computer. I am currently experienced only with uC based PCB and always thought it was just too complex to deal with MPU’s stuff.
This article is full of useful informations, well written, and absolutely a must read for young embedded engineers starting to deal with hardware design for Embedded Linux projects. Really really thank you for this valuable article.
Could you suggest if there is a complete tutorial for designing and programming an entry level board with V3s?
I’m curious on the discreet regulator version of the A33 board, did you handle sequencing somehow? Could you share that part of your schematic?
I didn’t need to power-sequence anything to get the board to reliably boot, but I didn’t do careful evaluations. The 3.3V and 2.5V linear regs on my board probably came up before my 1.35V DC/DC regulator, which is generally what you’d want anyway. If you were worried about it, throw RC filters on the enable pins and populate them if you have issues with boards coming up reliably.
Looks like that’s what’s been done on the RK3308 board I have. Thank you!
Any pointers for actually obtaining small quantities of these chips? I’ve been looking for the A33 and RK3308 and have not found many sellers that inspire confidence. We have a PnP and a low volume product, so we’d likely be building them in-house.
How did you managed to comply with the JLCPCB 4 layer stackup constraints? I mean the minimum via diameter is 0.45mm and the BGA ball pitch is 0.8mm so there is 0.35mm space between two vias in the fanout and the via to track clearance must be 0.254mm, thus it is impossible to me to use this 4 layer stackup for DDR routing.
Actually, for 4-layer and 6-layer boards, JLC does 3.5mil (0.09mm) min trace/space. Even using 4/4 mil trace width/space, you’ll have no issues. Also: breakout boards are pretty atypical since you’re escaping every single pin; for most designs that will only use a subset of I/O pins, you could probably get away with 5/5 rules and kind of nudge vias around to make things fit (there’s no rule that says your dogbone vias need to be on a 0.8mm-pitch grid).
While many of these parts are available on Digikey, & Mouser, etc. I’ve been looking for a source for the RockChip processors for about an hour and can’t one. Looked at the US distributors, eBay, Amazon, OctoPart, the RockChip website, & the JLCPCB Parts list. Nothing.
Please add links for where parts not easily available from the US distributors can be purchased.
And thank you so much for huge amount of work you did to write this very informative post.
You’re not going to find Rockchip or Allwinner parts anywhere other than local suppliers in the region. It can be a hassle to work with them directly during the prototyping phase of a project, so I typically just order parts from Taobao. Then when you go into production, basically any CM in East Asia should be able to track down the parts for you.
Thank you for this great post! I recently used the Allwinner V3s for an IoT project I’m working on. I am using Buildroot and mainline Linux. I found projects like Lichee Pi Zero and https://www.thirtythreeforty.net/posts/2019/12/my-business-card-runs-linux as great resources. I used full turn-key Chinese assembly (pcbway) to do my prototype because I’m not very confident in my hand SMD assembly skills. I’m interested in hearing your thoughts on doing production run with Chinese parts. I’m worried these chips will be hard to find. Should I be concerned?
you have done great work very detailed analysis for embedded linux building did you consider to release pcb design files so other peoples can jump start with it and start investigate further for their needs personally i also wanted to test SAM9X60 , SAMA5D27 , F1C200s and Allwinner V3s where i have nuc970 pcb already designed
Wow as a hobbyist this is so insanely complicated and so much work
I make stuff with cortex m4 etc as a hobby but this is just….. So much work and so complex
I think I’ll stick to high level computer programming! And my simplcus that only need 3-4 simple pins to work and power up xD
Hi, this is a great article, though I wish you would put the date at the top, and similarly with the MCU articles. This SOC is new and might be of interest:
https://www.cnx-software.com/2021/03/19/sigmastar-ssd210-tiny-dual-core-arm-cortex-a7-soc-64mb-ram-rgb-display/
There is a comparable Mediatek SOC used in this board:
https://www.seeedstudio.com/MT7628-Module-p-4821.html
Finally I think the Beagleboard Black and Pocketbeagle should be mentioned alongside the Raspberry Pi. They are older and not quite as cheap, but they are much more control oriented, have ADC’s and other i/o galore, have realtime coprocessors (PRU’s), etc.
Canada is rough for ordering electronics.
Techdesign’s 90% off thing for those chips is awesome, but the shipping is $20 for 5 chips that would fit in an envelope.
Wow, great article! Although i’m playing a lot ot OpenWRT router boards, and other embedded Linux instances, and i’ll pobably never design a full embedded system, it was worth to read it. A lot of stuff which will be useful, and well-written text. Thanks! 🙂
This article is so informative. You should publish more thing about this topic. Thank you so much!
Great detailed overview; massive thanks!
Thanks Jay for a stunning writeup. I stumbled across it by accident when looking for microprocessors with large ram. You have managed to cover all the critical questions with just the right amount of depth and balance – a veritable goldmine.
The manufacturers should pay you a commission- I dare say there was a spike in webpage hits for the covered chips especially Nuvoton who don’t seem to have much exposure outside Asia.
Your $1 micro article was also bang-on.
I look forward to your next offering – you touch on the subject of security which is a hot topic these days. Maybe that might be a topic served by your writing skills?
Have there been any new recommendations to add to this list as of late, parts that might be easier to obtain?
The thing is, I am a low-budget hobbyist just trying to hone her skills and expand her repertoire, so I don’t have any business-contacts or the likes through which to obtain parts. Most of the parts on this list are completely unavailable or just stupid-expensive — LCSC, for example, only has that Nuvoton – part available and none of the others. Elsewhere, 30€+ for e.g. those i.MX – parts? Yeahhh, no, can’t afford just for a single god damn component.
It took me a few days of reading and re-reading but I have finally made it down here. And honestly I am pretty disappointed that it is over, this has been such an eye opening read. I come with deep roots in the microcontroller world and have always viewed embedded linux as above my pay-grade. But You have done a great job of demystifying and breaking the ice.
I took a break after the SiP section to design my first embedded linux board! I figured that the NUC980 was the shortest leap (in terms of hardware) from my bread and butter. So I tossed together a nice little board (I think at least). I have an SD-card slot, SPI NOR flash and a host-lite USB port, along side a full breakout and a handful of LEDs. I even setup all the power sequencing. Boards are on the way and parts are in hand, so I am super excited!
The next step is the i.MX6 I think, I have a strange itch to fanout a BGA and to route and length match a DDR bus.
As a hardware engineer I am far more excited about the layout and design aspects than fiddling with linux but I am still excited to get to a terminal, after that, I’ll probably login and type ‘ls’, giggle to myself and put it in a box so that I can start designing the next board!
Anyway, Jay, thank you very much this is an epic piece of work. You have opened a whole new world for me, and I’d imagine many others.
What equipment did you use to get those Eye Diagrams, and what equipment would be necessary to measure reflections?
I am designing my first linux board with STM32MP1 0.8mm BGA. I have been designing boards with MCUs for 10 years now, but this is first MPU with external DDR, so of course most headache is with DDR routing. The problem is that if I would try getting ALL signals the same length, and distance 0.3mm between traces, on 4 layer board, the trace meanders would consume 2x more space on board than the MCU and DDR. It is clearly visible in ST’s own dev kits, where DDR is 9mm away from MPU to fit meanders, and traces go 30mm to the sides of a 13mm wide DDR chip. That is ridiculous. 30x50mm area just for MPU+DDR. Also ST has VTT terminations on all 25 AC lines, even with single DDR chip. I don’t believe this is all necessary. If I drop all trace length matching, distance 3S-thing and termination thing, I can put my DDR chip just 3mm from MPU, draw direct traces from MPU to DDR, and have Bank0 traces from 19 to 30mm, Bank1 traces from 15 to 19mm, and A/C lines from 8mm to 18mm, and be done. Would I really have any problems? I really don’t think so, but I want to see with my own eyes. So what equipment do I need?
Because to be honest, by making high speed traces as short as possible, I have always dodged any signal integrity issues. When device has USB, I just put MCU right next to USB connector; when it has RF, I just put transceiver right next to chip antenna/SMA connector. Can I weasel my way out this time as well?
Those are HyperLynx simulations, not measurements. You can’t take measurements like that without using an interposer (something like this), and even then, they wouldn’t be very accurate due to all the parasitics. I really can’t imagine you’d have any issues with what you’ve proposed; you definitely don’t need VTT termination. Back-of-the-envelope calculations: 30-19 = 11mm of skew, which is about 60 ps for a 5mil trace over a 0.1mm prepreg. DDR3-800 has a bit period of 1250 ps, so I think you’ll have plenty of margin.
Excellent article, Jay! As a newcomer to your site, I am impressed with the level of detail and yet at the same time the succinctness of your comprehensive overview of the field. This has likely saved TONS of headache and wasted effort for me and my team.
One common complaint I have about many blogs in general is particularly relevant to this one — *please put a date on it when you post*! From the comments, I deduce that you posted this in October 2020, about 10 months ago. Because of all of the supply chain consequences from global shutdowns, the prices in this article are no longer current, and some of these parts have year-long lead times. I for one would welcome an update. (Rabbit-holes, anyone? 🙂 )
Actually, here’s a suggestion for another blog article: any guidance / experience you have with the kind of supply chain issues (i.e. huge lead times, back-order hell, etc.) we’re seeing right now would be welcome. I’m finding it hard to know what the best approach is to select a microprocessor for my clients.
Thanks again for the GREAT article!
As a beginner of embedded Linux, the article alone is too much for me; however, it is very informative, it prepared me for avoiding any blunder.
Hi Jay!
This is so extremely interesting! I’ve long been interested in spinning my own Linux boards but was always too intimidated to get started. This discussion and comparison of different processors is by far the most coherent, beginner-friendly and end-to-end discussion of the topic I’ve encountered.
I would love to get started on a few of these processors. I’m mostly a hardware guy though – I don’t have any experience with the various software steps and hardware mapping stuff for getting Linux configured.
It would be amazing if you could make a video where you set up one of these from scratch in real time, up to the point where you actually boot the system. Having one full example to follow would be deeply educational. It would give me something to replicate and build on so I could try out other processors as well.
Thanks for the kind words! There are hundreds (or even thousands) of resources online — both in tutorial format and traditional documentation form — that will teach you everything you need to know. I really don’t have anything novel to contribute to this extensive collection of work.
Tutorials are especially challenging for a subject matter this broad; you might be able to quickly replicate the author’s work, but you will be copying-and-pasting commands that you don’t understand, which limits your ability to diagnose/debug things when stuff stops working (which it will). I generally tell my students to just grab a processor (start with a Raspberry Pi), download Buildroot, and literally just read the manual and work through it cold-turkey. The Buildroot manual is really quite good. You will undoubtedly run into issues, but they will likely come from extraneous knowledge gaps you’d need to fill in from other resources regardless. Good luck with your endeavors!
I used the AM3352 in a project. The main reason for picking it was the dual gig-Ethernet ports. It is actually a single controller with a 3-port L2 switch, but that works out to almost the same thing. This requirement severely limited the choices of processor. Anyway, I didn’t have any issues at all with bringing up the board which were not of my own doing : swapping uds/lds to ddr, like that never happens. Because we are a deep-embedded application, we stripped out most of the bloaty uboot-dts-kernel stuff, and the major issues I have had to do with linux itself, which is basically bloaty and kludgy,. but that is well beyond the scope of this article.
Hello Everyone,
I am very inexperienced in basically any hardware design, even with microcontrollers, but I have wanted to work with microprocessors for about a year now, and have read this article about 5 times. And so far I created a very simple board here: https://drive.google.com/file/d/15JMh2n5gaapboxCrrF6j-LXfBUjcSB1Y/view?usp=sharing, I know that it looks bad but the point is just to make it boot, can anyone tell me if there is something wrong with it, before I send it to JLCPCB for fabricating? It is a board meant to use the Allwinner A83T, more powerful that Raspi 4, I based it off of Olinuxino A64 Board, and Banana M3 Schematic. Few side notes if anyone can help me, I used a different PMIC than recommended, the AXP818 because I don’t need the extra audio codec. Also I didn’t length tune the ram, because the distance between the processor and ram is 20mm, less than the max length difference. Or if anyone can route me to a better site to ask this it would be appreciated.
I need a linux device, with gcc, bash, ssh etc.
AND a week or month working time on one charge. not hours but week
I can run linux on 256MiB ram, no wifi always time, 16-30MHz is ok but I need long time working time in mobile mode. This is a value.
YOOHOOOO what a great page that i found..
BEST REGARDS sir..
thank you SooOoOoO Much ( ∞ )
Nerves (https://www.nerves-project.org/) offers a way to develop special-purpose Linux systems for embedded and IoT use. As I understand it, the toolchain builds OS images on a separate machine, then loads them into a read-only boot partition on the target machine. So, if a new image crashes, the target can be rebooted using another boot partition.
Because Nerves is based on Elixir (https://elixir-lang.org/, https://en.wikipedia.org/wiki/Elixir_(programming_language)), it has support for concurrency, distribution, failsoft operation, etc. In fact, the target OS itself is supported by a supervision tree, so if a key programs fail, they can be restarted automagically.
A triumph of clear writing.
Awesome post. I really enjoyed it.
Please consider a video showing how you build a PCB from start to finish. You don’t need to explain everything as you do it, but I’d enjoy watching a pro like you put a board together. Maybe start with a SIP so it’s not too long, but I’d like to see you route DDR signals too at some point.
This is an amazing resource, thank you!
I share the same desire as ‘PETE’ in the comment above me. Would be really awesome if you could make a video on board design (maybe a small course or something) would gladly pay for such resources
One stop reference. Great article.
This is a fantastic write up, I really want now to try building my own embedded Linux board.
I would love to hear your thoughts about the Allwinner D1 RISC-V processor, maybe consider it for your next part?
This is a fantastic write up, I really want now to try build my own embedded Linux board.
I would love to hear your thoughts about the Allwinner D1 RISC-V processor, maybe consider it for your next part?
Amazing Article !
I am also deep into hardware and embedded SW but i must confess I learnt a lot in it !
Thanks
Jacques
Nice write-up! Thanks for sharing!
Quick question- How would you approach device driver for SPI master (1) with multiple slaves (8 or more)?
I’m aware of cadence DT binding that provides attribute ‘is-decoded-cs’… but, haven’t found and example/implementation for above scenario.
In any event, thanks again for sharing!
Great article. I learned a ton. Thank you!
Thanks for this, having worked on many embedded development projects through my job, its great to see so much overview. Would be great if you could take us through how you put together a simple system design from start to finish, say a network camera or somthing like that. I buy that as a book. Thanks again.
Hi Jay, what an amazing dive into the world of Linux-enabled hardware design! I’m a software person myself and I’d love to dabble into what you do, but I never found the time for that (despite working in a technical university just like yourself). Kudos for this brilliantly put together article.
Very useful post!
How did you manage to power the STM32MP1 with only two regulators (3.3V and 1.35V)? I might be missing something but
isn’t VDD_CORE limited to 1.29V?
ST makes several STM32MP1 parts, but the one I used is from the older 15x series that tops out at 800 MHz. I think you’re looking at the new 1 GHz parts that now have a separate VDD_CPU rail bonded out (probably for lower power consumption, since it allows you to run the rest of the core logic at a lower voltage).
You should be able to tie that to VDD_CORE and run them at 1.35V, though you’ll have increased power consumption. Both rails have an absolute max of 1.5V.
Thank you, Jay Carlson, for sharing this enlightening article on embedded Linux. Your in-depth exploration of the topic, from the fundamentals to practical considerations, offers a wealth of knowledge for both beginners and experienced developers. The clear explanations and real-world examples provide valuable insights into harnessing the power of Linux in embedded systems. Your efforts in sharing this information are greatly appreciated and will undoubtedly benefit the embedded systems community.
“working on the Rockchip RK3308, I was flying through things. I spent two hours researching, 20 minutes drawing the 355-pin schematic symbol, an hour routing the DDR3 bus, three hours fanning out the rest of the signals and routing power, and 30 minutes cleaning everything up.” I’d like to see that.. the timing, don’t believe that 🙂
Found this page while searching for info regarding the RK3308. Very interesting read.
Like mentioned in the text, my main concern for not starting a board from scratch (instead of a som) was SDRAM interfacing and the pcb fab requirements associated with bga. As in, spending a lot on pcb fab only to end up with a design that doesn’t work but no idea why…
But decided to try anyway with the rk3308 (fairly cheap, low power compared to others I can find). But can’t find the required docs for it. So, where did you find the footprint/layout for the component?
Furthermore, I’ve found the TRM’s but those don’t include any hardware reference designs…
After reading the article I decided to have a go at designing a board around the RK3308…
But I’m kinda stuck on the ram address lines, lengths go from 13,6mm to 20mm. Probably should start over?
Would it be possible for you to share your design? Managed to get the rest routed (emmc,phy,dcdc etc)
Great guide. Most important of all it gave me confidence. Got a cheapo v3s board running with ethernet / usb / uart at least tested. I got a lot out of the experience, major mistakes: I managed to not pull my boot pin high (I misread the data sheet when it said no pull), but I broke out all the pins so wasn’t bad to fix. Also my voltage regulators required 5.5 volts, so nothing turned on when I applied the 5 volt usb power, once again since I broke everything out I just wired it to a 5.6 volt supply. It’s janky, but it worked. Ethernet was a bit tricky, had to edit the dts, but would have been a disaster had I messed up in HW and not read what you wrote about the inductor haha.
I feel like version control with buildroot is a nightmare (they want me to write a git patch??) I pulled custom config/dts stuff out which I assume is what everyone does so I could commit to my monorepo, then tarred the buildroot folder to a fileshare and put it into gitignore. Argument was don’t want to download things everytime i want to build the image, and I needed a specific buildroot ver for the v3s that will hopefully be unchanged. Not sure best route here, if anyone has any input on how they do it I’d be interested. I think next board I’m going to try to build everything without buildroot (except maybe just to bootstrap as a sanity) and choose a chip in linux mainline.
Hi!
Just to give a clarification on the fact that a STM32F746 advertises an unexpected number of DMIPS, it hosts an M7 arm core, which is 32 bit, but is able, through a 64 bit bus, to perform double issues in load/load and load/store assembly instructions.
Of course if the compiler is abel to exploit this characteristics. And the internal memory of STM32F476 has a 64 bit data bus.
Hoping to be of help, best regards!